Multilevel Modelling with Variational Inference¶
There have been two reasons for writing this notebook -
- To have a port of Multilevel modelling from PyMC3 to PyMC4.
- To test the Variational Inference API added this summer.
Radon contamination (Gelman and Hill 2006)¶
Radon is a radioactive gas that enters homes through contact points with the ground. It is a carcinogen that is the primary cause of lung cancer in non-smokers. Radon levels vary greatly from household to household. The EPA did a study of radon levels in 80,000 houses. There are two important predictors:
Measurement in basement or first floor (radon higher in basements)
Measurement of Uranium level available at county level
We will focus on modeling radon levels in Minnesota. The hierarchy in this example is households within county.
The model building has been inspired from TFP port of Multilevel modelling and the visualizations have been borrowed from PyMC3's Multilevel modelling.
import arviz as az
import logging
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc4 as pm
import tensorflow as tf
import xarray as xr
from tensorflow_probability import bijectors as tfb
logging.getLogger("tensorflow").setLevel(logging.ERROR)
%config InlineBackend.figure_format = 'retina'
RANDOM_SEED = 8927
np.random.seed(RANDOM_SEED)
az.style.use('arviz-darkgrid')
Let's fetch the data and start analysing -
data = pd.read_csv(pm.utils.get_data('radon.csv'))
u = np.log(data.Uppm).unique()
mn_counties = data.county.unique()
floor = data.floor.values.astype(np.int32)
counties = len(mn_counties)
county_lookup = dict(zip(mn_counties, range(counties)))
county_idx = data['county_code'].values.astype(np.int32)
data.head()
| Unnamed: 0 | idnum | state | state2 | stfips | zip | region | typebldg | floor | room | ... | pcterr | adjwt | dupflag | zipflag | cntyfips | county | fips | Uppm | county_code | log_radon | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 5081.0 | MN | MN | 27.0 | 55735 | 5.0 | 1.0 | 1.0 | 3.0 | ... | 9.7 | 1146.499190 | 1.0 | 0.0 | 1.0 | AITKIN | 27001.0 | 0.502054 | 0 | 0.832909 |
| 1 | 1 | 5082.0 | MN | MN | 27.0 | 55748 | 5.0 | 1.0 | 0.0 | 4.0 | ... | 14.5 | 471.366223 | 0.0 | 0.0 | 1.0 | AITKIN | 27001.0 | 0.502054 | 0 | 0.832909 |
| 2 | 2 | 5083.0 | MN | MN | 27.0 | 55748 | 5.0 | 1.0 | 0.0 | 4.0 | ... | 9.6 | 433.316718 | 0.0 | 0.0 | 1.0 | AITKIN | 27001.0 | 0.502054 | 0 | 1.098612 |
| 3 | 3 | 5084.0 | MN | MN | 27.0 | 56469 | 5.0 | 1.0 | 0.0 | 4.0 | ... | 24.3 | 461.623670 | 0.0 | 0.0 | 1.0 | AITKIN | 27001.0 | 0.502054 | 0 | 0.095310 |
| 4 | 4 | 5085.0 | MN | MN | 27.0 | 55011 | 3.0 | 1.0 | 0.0 | 4.0 | ... | 13.8 | 433.316718 | 0.0 | 0.0 | 3.0 | ANOKA | 27003.0 | 0.428565 | 1 | 1.163151 |
5 rows × 30 columns
Conventional approaches¶
Before comparing ADVI approximations on hierarchical models, lets model radon exposure by conventional approaches -
Complete pooling:¶
Treat all counties the same, and estimate a single radon level. $$ y_i = \alpha + \beta x_i + \epsilon_i $$ where $y_i$ is the logarithm of radon level in house $i$, $x_i$ is the floor of measurement (either basement or first floor) and $\epsilon_i$ are the errors representing measurement error, temporal within-house variation, or variation among houses. The model directly translates to PyMC4 as -
@pm.model
def pooled_model():
a = yield pm.Normal('a', loc=0.0, scale=10.0, batch_stack=2)
loc = a[0] + a[1]*floor
scale = yield pm.Exponential("sigma", rate=1.0)
y = yield pm.Normal('y', loc=loc, scale=scale, observed=data.log_radon.values)
Before running the model let’s do some prior predictive checks. These help in incorporating scientific knowledge into our model.
prior_checks = pm.sample_prior_predictive(pooled_model())
prior_checks
-
- chain: 1
- draw: 1000
- pooled_model/a_dim_0: 2
- pooled_model/y_dim_0: 919
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 5 ... 995 996 997 998 999
array([ 0, 1, 2, ..., 997, 998, 999])
- pooled_model/a_dim_0(pooled_model/a_dim_0)int640 1
array([0, 1])
- pooled_model/y_dim_0(pooled_model/y_dim_0)int640 1 2 3 4 5 ... 914 915 916 917 918
array([ 0, 1, 2, ..., 916, 917, 918])
- pooled_model/a(chain, draw, pooled_model/a_dim_0)float323.7358973 -15.320486 ... -6.4341984
array([[[ 3.7358973 , -15.320486 ], [ -8.676756 , 12.327385 ], [ 7.349168 , -11.632883 ], ..., [-17.763176 , 3.9943478 ], [-21.435543 , -0.07876515], [ 6.5087595 , -6.4341984 ]]], dtype=float32) - pooled_model/sigma(chain, draw)float320.124252275 ... 0.1704529
array([[1.24252275e-01, 2.18166053e-01, 1.73134065e+00, 1.87080002e+00, 3.86758149e-01, 5.85898086e-02, 6.60767257e-01, 2.19248462e+00, 1.47937405e+00, 2.62981963e+00, 4.73047018e+00, 9.72903013e-01, 2.52875018e+00, 8.60245943e-01, 8.71204972e-01, 1.35467723e-01, 1.69988155e+00, 7.30032027e-02, 9.49807644e-01, 1.09355628e+00, 3.70404184e-01, 3.09200644e+00, 2.13690877e-01, 2.92978317e-01, 3.86870742e+00, 9.20100808e-01, 1.02149987e+00, 2.77314210e+00, 2.70368147e+00, 1.73186255e+00, 1.76331401e+00, 4.39246774e-01, 1.77190304e+00, 2.80357766e+00, 5.52719057e-01, 2.90537804e-01, 1.94052780e+00, 1.34999350e-01, 2.91218370e-01, 5.11170149e-01, 1.15133429e+00, 1.17300548e-01, 5.86179018e-01, 5.14345884e-01, 8.83724809e-01, 7.76633382e-01, 1.10540688e+00, 1.08257413e-01, 5.25177084e-02, 3.14549160e+00, 6.67104274e-02, 4.64121342e-01, 7.31377482e-01, 1.71201837e+00, 1.87058103e+00, 2.11804080e+00, 6.23107910e-01, 1.00311029e+00, 1.93300366e-01, 4.71577160e-02, 3.09122745e-02, 9.28924203e-01, 9.97797132e-01, 2.21684054e-01, 1.07126725e+00, 6.38897419e-01, 8.48415494e-01, 1.69924951e+00, 3.50955153e+00, 2.81853676e+00, 1.37188005e+00, 2.09045768e-01, 9.41089094e-01, 4.14538980e-01, 2.02648091e+00, 1.84433746e+00, 8.94062296e-02, 1.76502556e-01, 4.57081646e-01, 1.40374005e+00, ... 1.14232793e-01, 7.78646648e-01, 3.45841944e-01, 3.75480473e-01, 1.28782916e+00, 4.15802926e-01, 8.08096603e-02, 5.22279032e-02, 8.44400525e-01, 1.47122109e+00, 2.81988353e-01, 3.39085937e+00, 2.95001197e+00, 1.06472814e+00, 3.15820456e-01, 4.45387554e+00, 5.07715106e-01, 1.19484656e-01, 1.16057575e+00, 3.00743866e+00, 1.65124059e+00, 5.88920474e-01, 3.90195608e-01, 3.77834588e-01, 1.22497284e+00, 2.00244546e-01, 4.09505934e-01, 8.67544949e-01, 5.33267632e-02, 8.05767238e-01, 2.12663269e+00, 3.38898778e-01, 4.54715788e-01, 8.15032780e-01, 4.91176903e-01, 9.15093780e-01, 1.57230064e-01, 1.38862503e+00, 1.08501464e-01, 6.69538558e-01, 8.17155182e-01, 1.05785382e+00, 9.57605004e-01, 9.24436986e-01, 4.19909686e-01, 1.45669365e+00, 4.69646358e+00, 3.91691655e-01, 3.20592582e-01, 6.58347085e-02, 1.61505580e-01, 5.05329669e-01, 8.30124795e-01, 4.04626340e-01, 1.40436232e+00, 2.45392132e+00, 2.53958583e-01, 8.45379829e-01, 3.96697491e-01, 1.41434446e-01, 5.29461503e-01, 2.00267315e+00, 6.58604681e-01, 1.73856175e+00, 5.13490498e-01, 1.29534507e+00, 5.09042621e-01, 2.11369276e+00, 5.72610974e-01, 1.51463377e+00, 1.18161130e+00, 2.33294666e-01, 1.43027735e+00, 1.33725750e+00, 3.33844095e-01, 1.70452893e-01]], dtype=float32) - pooled_model/y(chain, draw, pooled_model/y_dim_0)float32-11.425111 3.614398 ... 6.6331916
array([[[-11.425111 , 3.614398 , 3.709121 , ..., 3.78737 , 3.7087603 , 3.7606945 ], [ 3.6845543 , -8.816672 , -9.096872 , ..., -8.230866 , -8.635344 , -8.8506 ], [ -1.7254968 , 9.610426 , 6.3633847 , ..., 7.3794913 , 6.3264837 , 7.831397 ], ..., [-12.150305 , -19.475933 , -15.784439 , ..., -14.951879 , -21.717302 , -16.133024 ], [-21.319092 , -20.926788 , -20.77283 , ..., -21.46507 , -22.080853 , -21.092203 ], [ 0.30990508, 6.4175243 , 6.4763956 , ..., 6.4609776 , 6.825876 , 6.6331916 ]]], dtype=float32)
- created_at :
- 2020-09-06T15:12:11.500262
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (chain: 1, draw: 1000, pooled_model/a_dim_0: 2, pooled_model/y_dim_0: 919) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 6 ... 994 995 996 997 998 999 * pooled_model/a_dim_0 (pooled_model/a_dim_0) int64 0 1 * pooled_model/y_dim_0 (pooled_model/y_dim_0) int64 0 1 2 3 ... 916 917 918 Data variables: pooled_model/a (chain, draw, pooled_model/a_dim_0) float32 3.73589... pooled_model/sigma (chain, draw) float32 0.124252275 ... 0.1704529 pooled_model/y (chain, draw, pooled_model/y_dim_0) float32 -11.425... Attributes: created_at: 2020-09-06T15:12:11.500262 arviz_version: 0.9.0xarray.Dataset
To make our lives easier during plotting and diagonsing while using ArviZ, we define a function remove_scope for renaming all variables in InferenceData to their actual distribution name.
def remove_scope(idata):
for group in idata._groups:
for var in getattr(idata, group).variables:
if "/" in var:
idata.rename(name_dict={var: var.split("/")[-1]}, inplace=True)
idata.rename(name_dict={"y_dim_0": "obs_id"}, inplace=True)
remove_scope(prior_checks)
prior_checks
-
- a_dim_0: 2
- chain: 1
- draw: 1000
- obs_id: 919
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 5 ... 995 996 997 998 999
array([ 0, 1, 2, ..., 997, 998, 999])
- a_dim_0(a_dim_0)int640 1
array([0, 1])
- obs_id(obs_id)int640 1 2 3 4 5 ... 914 915 916 917 918
array([ 0, 1, 2, ..., 916, 917, 918])
- a(chain, draw, a_dim_0)float323.7358973 -15.320486 ... -6.4341984
array([[[ 3.7358973 , -15.320486 ], [ -8.676756 , 12.327385 ], [ 7.349168 , -11.632883 ], ..., [-17.763176 , 3.9943478 ], [-21.435543 , -0.07876515], [ 6.5087595 , -6.4341984 ]]], dtype=float32) - sigma(chain, draw)float320.124252275 ... 0.1704529
array([[1.24252275e-01, 2.18166053e-01, 1.73134065e+00, 1.87080002e+00, 3.86758149e-01, 5.85898086e-02, 6.60767257e-01, 2.19248462e+00, 1.47937405e+00, 2.62981963e+00, 4.73047018e+00, 9.72903013e-01, 2.52875018e+00, 8.60245943e-01, 8.71204972e-01, 1.35467723e-01, 1.69988155e+00, 7.30032027e-02, 9.49807644e-01, 1.09355628e+00, 3.70404184e-01, 3.09200644e+00, 2.13690877e-01, 2.92978317e-01, 3.86870742e+00, 9.20100808e-01, 1.02149987e+00, 2.77314210e+00, 2.70368147e+00, 1.73186255e+00, 1.76331401e+00, 4.39246774e-01, 1.77190304e+00, 2.80357766e+00, 5.52719057e-01, 2.90537804e-01, 1.94052780e+00, 1.34999350e-01, 2.91218370e-01, 5.11170149e-01, 1.15133429e+00, 1.17300548e-01, 5.86179018e-01, 5.14345884e-01, 8.83724809e-01, 7.76633382e-01, 1.10540688e+00, 1.08257413e-01, 5.25177084e-02, 3.14549160e+00, 6.67104274e-02, 4.64121342e-01, 7.31377482e-01, 1.71201837e+00, 1.87058103e+00, 2.11804080e+00, 6.23107910e-01, 1.00311029e+00, 1.93300366e-01, 4.71577160e-02, 3.09122745e-02, 9.28924203e-01, 9.97797132e-01, 2.21684054e-01, 1.07126725e+00, 6.38897419e-01, 8.48415494e-01, 1.69924951e+00, 3.50955153e+00, 2.81853676e+00, 1.37188005e+00, 2.09045768e-01, 9.41089094e-01, 4.14538980e-01, 2.02648091e+00, 1.84433746e+00, 8.94062296e-02, 1.76502556e-01, 4.57081646e-01, 1.40374005e+00, ... 1.14232793e-01, 7.78646648e-01, 3.45841944e-01, 3.75480473e-01, 1.28782916e+00, 4.15802926e-01, 8.08096603e-02, 5.22279032e-02, 8.44400525e-01, 1.47122109e+00, 2.81988353e-01, 3.39085937e+00, 2.95001197e+00, 1.06472814e+00, 3.15820456e-01, 4.45387554e+00, 5.07715106e-01, 1.19484656e-01, 1.16057575e+00, 3.00743866e+00, 1.65124059e+00, 5.88920474e-01, 3.90195608e-01, 3.77834588e-01, 1.22497284e+00, 2.00244546e-01, 4.09505934e-01, 8.67544949e-01, 5.33267632e-02, 8.05767238e-01, 2.12663269e+00, 3.38898778e-01, 4.54715788e-01, 8.15032780e-01, 4.91176903e-01, 9.15093780e-01, 1.57230064e-01, 1.38862503e+00, 1.08501464e-01, 6.69538558e-01, 8.17155182e-01, 1.05785382e+00, 9.57605004e-01, 9.24436986e-01, 4.19909686e-01, 1.45669365e+00, 4.69646358e+00, 3.91691655e-01, 3.20592582e-01, 6.58347085e-02, 1.61505580e-01, 5.05329669e-01, 8.30124795e-01, 4.04626340e-01, 1.40436232e+00, 2.45392132e+00, 2.53958583e-01, 8.45379829e-01, 3.96697491e-01, 1.41434446e-01, 5.29461503e-01, 2.00267315e+00, 6.58604681e-01, 1.73856175e+00, 5.13490498e-01, 1.29534507e+00, 5.09042621e-01, 2.11369276e+00, 5.72610974e-01, 1.51463377e+00, 1.18161130e+00, 2.33294666e-01, 1.43027735e+00, 1.33725750e+00, 3.33844095e-01, 1.70452893e-01]], dtype=float32) - y(chain, draw, obs_id)float32-11.425111 3.614398 ... 6.6331916
array([[[-11.425111 , 3.614398 , 3.709121 , ..., 3.78737 , 3.7087603 , 3.7606945 ], [ 3.6845543 , -8.816672 , -9.096872 , ..., -8.230866 , -8.635344 , -8.8506 ], [ -1.7254968 , 9.610426 , 6.3633847 , ..., 7.3794913 , 6.3264837 , 7.831397 ], ..., [-12.150305 , -19.475933 , -15.784439 , ..., -14.951879 , -21.717302 , -16.133024 ], [-21.319092 , -20.926788 , -20.77283 , ..., -21.46507 , -22.080853 , -21.092203 ], [ 0.30990508, 6.4175243 , 6.4763956 , ..., 6.4609776 , 6.825876 , 6.6331916 ]]], dtype=float32)
- created_at :
- 2020-09-06T15:12:11.500262
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (a_dim_0: 2, chain: 1, draw: 1000, obs_id: 919) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 6 7 8 ... 992 993 994 995 996 997 998 999 * a_dim_0 (a_dim_0) int64 0 1 * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 ... 911 912 913 914 915 916 917 918 Data variables: a (chain, draw, a_dim_0) float32 3.7358973 -15.320486 ... -6.4341984 sigma (chain, draw) float32 0.124252275 0.21816605 ... 0.1704529 y (chain, draw, obs_id) float32 -11.425111 3.614398 ... 6.6331916 Attributes: created_at: 2020-09-06T15:12:11.500262 arviz_version: 0.9.0xarray.Dataset
_, ax = plt.subplots()
prior_checks.assign_coords(coords={"a_dim_0": ["Basement", " First Floor"]}, inplace=True)
prior_checks.prior_predictive.plot.scatter(x="a_dim_0", y="a", color="k", alpha=0.2, ax=ax)
ax.set(xlabel="Level", ylabel="Radon level (Log Scale)");

As there is no coords and dims integration to PyMC4's ModelTemplate, we need a bit extra manipulations to handle them. Here we need to assign_coords to dimensions of variable a to consider Basement and First Floor.
Before seeing the data, these priors seem to allow for quite a wide range of the mean log radon level. Let's fire up Variational Inference machinery and fit the model -
pooled_advi = pm.fit(pooled_model(), num_steps=25_000)
|>>>>>>>>>>>>>>>>>>>>|
def plot_elbo(loss):
plt.plot(loss)
plt.yscale("log")
plt.xlabel("Number of iterations")
plt.ylabel("Negative log(ELBO)")
plot_elbo(pooled_advi.losses)

Looks good, ELBO seems to have converged. As a sanity check, we will plot ELBO each time after fitting a new model to figure out its convergence.
Now, we'll draw samples from the posterior distribution. And then, pass these samples to sample_posterior_predictive to estimate the uncertainty at Basement and First Floor radon levels.
pooled_advi_samples = pooled_advi.approximation.sample(2_000)
pooled_advi_samples
-
- chain: 1
- draw: 2000
- pooled_model/a_dim_0: 2
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- pooled_model/a_dim_0(pooled_model/a_dim_0)int640 1
array([0, 1])
- pooled_model/a(chain, draw, pooled_model/a_dim_0)float321.4208013 ... -0.6438127
array([[[ 1.4208013 , -0.50706375], [ 1.4203647 , -0.52226704], [ 1.4275815 , -0.52768236], ..., [ 1.3540957 , -0.6212556 ], [ 1.3802642 , -0.6262389 ], [ 1.3690256 , -0.6438127 ]]], dtype=float32) - pooled_model/__log_sigma(chain, draw)float32-0.262588 ... -0.23297022
array([[-0.262588 , -0.24097891, -0.22231792, ..., -0.28082496, -0.22691318, -0.23297022]], dtype=float32) - pooled_model/sigma(chain, draw)float320.7690587 0.7858582 ... 0.79217714
array([[0.7690587 , 0.7858582 , 0.8006608 , ..., 0.7551605 , 0.79699 , 0.79217714]], dtype=float32)
- created_at :
- 2020-09-06T15:12:24.652480
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (chain: 1, draw: 2000, pooled_model/a_dim_0: 2) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 ... 1996 1997 1998 1999 * pooled_model/a_dim_0 (pooled_model/a_dim_0) int64 0 1 Data variables: pooled_model/a (chain, draw, pooled_model/a_dim_0) float32 1.4... pooled_model/__log_sigma (chain, draw) float32 -0.262588 ... -0.23297022 pooled_model/sigma (chain, draw) float32 0.7690587 ... 0.79217714 Attributes: created_at: 2020-09-06T15:12:24.652480 arviz_version: 0.9.0xarray.Dataset -
- pooled_model/y_dim_0: 919
- pooled_model/y_dim_0(pooled_model/y_dim_0)int640 1 2 3 4 5 ... 914 915 916 917 918
array([ 0, 1, 2, ..., 916, 917, 918])
- pooled_model/y(pooled_model/y_dim_0)float640.8329 0.8329 1.099 ... 1.335 1.099
array([ 0.83290912, 0.83290912, 1.09861229, 0.09531018, 1.16315081, 0.95551145, 0.47000363, 0.09531018, -0.22314355, 0.26236426, 0.26236426, 0.33647224, 0.40546511, -0.69314718, 0.18232156, 1.5260563 , 0.33647224, 0.78845736, 1.79175947, 1.22377543, 0.64185389, 1.70474809, 1.85629799, 0.69314718, 1.90210753, 1.16315081, 1.93152141, 1.96009478, 2.05412373, 1.66770682, 1.5260563 , 1.5040774 , 1.06471074, 2.10413415, 0.53062825, 1.45861502, 1.70474809, 1.41098697, 0.87546874, 1.09861229, 0.40546511, 1.22377543, 1.09861229, 0.64185389, -1.2039728 , 0.91629073, 0.18232156, 0.83290912, -0.35667494, 0.58778666, 1.09861229, 0.83290912, 0.58778666, 0.40546511, 0.69314718, 0.64185389, 0.26236426, 1.48160454, 1.5260563 , 1.85629799, 1.54756251, 1.75785792, 0.83290912, -0.69314718, 1.54756251, 1.5040774 , 1.90210753, 1.02961942, 1.09861229, 1.09861229, 1.98787435, 1.62924054, 0.99325177, 1.62924054, 2.57261223, 1.98787435, 1.93152141, 2.55722731, 1.77495235, 2.2617631 , 1.80828877, 1.36097655, 2.66722821, 0.64185389, 1.94591015, 1.56861592, 2.2617631 , 0.95551145, 1.91692261, 1.41098697, 2.32238772, 0.83290912, 0.64185389, 1.25276297, 1.74046617, 1.48160454, 1.38629436, 0.33647224, 1.45861502, -0.10536052, ... 1.80828877, 1.09861229, 1.91692261, 2.96527307, 1.41098697, 1.79175947, 2.20827441, 2.14006616, 0.18232156, 1.16315081, 2.4510051 , 2.27212589, 1.09861229, -0.22314355, 1.19392247, 1.56861592, 1.58923521, -0.69314718, 2.24070969, 0.58778666, 0. , 2.3321439 , 2.05412373, 0.83290912, 1.88706965, 2.50959926, 1.54756251, 1.84054963, 1.88706965, 1.06471074, 0.69314718, 0.26236426, 0.91629073, 0.09531018, 0.26236426, 0.53062825, -0.10536052, 0.58778666, 1.56861592, 0.58778666, 1.22377543, -0.10536052, 2.29253476, 1.68639895, 2.1517622 , 0.69314718, 1.90210753, 1.36097655, 1.79175947, 1.60943791, 0.95551145, 2.37954613, 0.91629073, 0.78845736, 1.56861592, 1.33500107, 2.60268969, 1.09861229, 1.48160454, 1.36097655, 0.64185389, 0.47000363, 0.64185389, 0.33647224, 1.90210753, 3.02042489, 1.80828877, 2.63188884, 2.3321439 , 1.75785792, 2.24070969, 1.25276297, 1.43508453, 2.45958884, 1.98787435, 1.56861592, 0.64185389, -0.22314355, 1.56861592, 2.3321439 , 2.43361336, 2.04122033, 2.4765384 , -0.51082562, 1.91692261, 1.68639895, 1.16315081, 0.78845736, 2.00148 , 1.64865863, 0.83290912, 0.87546874, 2.77258872, 2.2617631 , 1.87180218, 1.5260563 , 1.62924054, 1.33500107, 1.09861229])
- created_at :
- 2020-09-06T15:12:24.654109
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (pooled_model/y_dim_0: 919) Coordinates: * pooled_model/y_dim_0 (pooled_model/y_dim_0) int64 0 1 2 3 ... 916 917 918 Data variables: pooled_model/y (pooled_model/y_dim_0) float64 0.8329 0.8329 ... 1.099 Attributes: created_at: 2020-09-06T15:12:24.654109 arviz_version: 0.9.0xarray.Dataset
posterior_predictive = pm.sample_posterior_predictive(pooled_model(), pooled_advi_samples)
remove_scope(posterior_predictive)
posterior_predictive
-
- a_dim_0: 2
- chain: 1
- draw: 2000
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- a_dim_0(a_dim_0)int640 1
array([0, 1])
- a(chain, draw, a_dim_0)float321.4208013 ... -0.6438127
array([[[ 1.4208013 , -0.50706375], [ 1.4203647 , -0.52226704], [ 1.4275815 , -0.52768236], ..., [ 1.3540957 , -0.6212556 ], [ 1.3802642 , -0.6262389 ], [ 1.3690256 , -0.6438127 ]]], dtype=float32) - __log_sigma(chain, draw)float32-0.262588 ... -0.23297022
array([[-0.262588 , -0.24097891, -0.22231792, ..., -0.28082496, -0.22691318, -0.23297022]], dtype=float32) - sigma(chain, draw)float320.7690587 0.7858582 ... 0.79217714
array([[0.7690587 , 0.7858582 , 0.8006608 , ..., 0.7551605 , 0.79699 , 0.79217714]], dtype=float32)
- created_at :
- 2020-09-06T15:12:24.652480
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (a_dim_0: 2, chain: 1, draw: 2000) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 6 ... 1994 1995 1996 1997 1998 1999 * a_dim_0 (a_dim_0) int64 0 1 Data variables: a (chain, draw, a_dim_0) float32 1.4208013 ... -0.6438127 __log_sigma (chain, draw) float32 -0.262588 -0.24097891 ... -0.23297022 sigma (chain, draw) float32 0.7690587 0.7858582 ... 0.79217714 Attributes: created_at: 2020-09-06T15:12:24.652480 arviz_version: 0.9.0xarray.Dataset -
- chain: 1
- draw: 2000
- obs_id: 919
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- obs_id(obs_id)int640 1 2 3 4 5 ... 914 915 916 917 918
array([ 0, 1, 2, ..., 916, 917, 918])
- y(chain, draw, obs_id)float320.8419045 0.9926412 ... 0.36609662
array([[[ 0.8419045 , 0.9926412 , 2.3756475 , ..., 2.6291053 , 0.52533627, 2.0592532 ], [ 0.24704647, 0.86674404, 1.573486 , ..., 1.0467045 , 0.03541672, 1.5265828 ], [ 0.64094734, 2.8461373 , 1.59538 , ..., 1.4419069 , 2.3063586 , 1.2692662 ], ..., [ 0.20850796, 2.1369853 , 1.350267 , ..., 0.96725345, 2.351105 , 2.197761 ], [ 1.2758532 , 1.1836511 , -0.5104476 , ..., 0.55777067, 1.732587 , 0.874024 ], [ 0.44130206, 0.70061743, 0.7445947 , ..., 1.6418209 , 3.2866702 , 0.36609662]]], dtype=float32)
- created_at :
- 2020-09-06T15:12:25.247406
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (chain: 1, draw: 2000, obs_id: 919) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 6 7 ... 1993 1994 1995 1996 1997 1998 1999 * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 ... 911 912 913 914 915 916 917 918 Data variables: y (chain, draw, obs_id) float32 0.8419045 0.9926412 ... 0.36609662 Attributes: created_at: 2020-09-06T15:12:25.247406 arviz_version: 0.9.0xarray.Dataset -
- obs_id: 919
- obs_id(obs_id)int640 1 2 3 4 5 ... 914 915 916 917 918
array([ 0, 1, 2, ..., 916, 917, 918])
- y(obs_id)float640.8329 0.8329 1.099 ... 1.335 1.099
array([ 0.83290912, 0.83290912, 1.09861229, 0.09531018, 1.16315081, 0.95551145, 0.47000363, 0.09531018, -0.22314355, 0.26236426, 0.26236426, 0.33647224, 0.40546511, -0.69314718, 0.18232156, 1.5260563 , 0.33647224, 0.78845736, 1.79175947, 1.22377543, 0.64185389, 1.70474809, 1.85629799, 0.69314718, 1.90210753, 1.16315081, 1.93152141, 1.96009478, 2.05412373, 1.66770682, 1.5260563 , 1.5040774 , 1.06471074, 2.10413415, 0.53062825, 1.45861502, 1.70474809, 1.41098697, 0.87546874, 1.09861229, 0.40546511, 1.22377543, 1.09861229, 0.64185389, -1.2039728 , 0.91629073, 0.18232156, 0.83290912, -0.35667494, 0.58778666, 1.09861229, 0.83290912, 0.58778666, 0.40546511, 0.69314718, 0.64185389, 0.26236426, 1.48160454, 1.5260563 , 1.85629799, 1.54756251, 1.75785792, 0.83290912, -0.69314718, 1.54756251, 1.5040774 , 1.90210753, 1.02961942, 1.09861229, 1.09861229, 1.98787435, 1.62924054, 0.99325177, 1.62924054, 2.57261223, 1.98787435, 1.93152141, 2.55722731, 1.77495235, 2.2617631 , 1.80828877, 1.36097655, 2.66722821, 0.64185389, 1.94591015, 1.56861592, 2.2617631 , 0.95551145, 1.91692261, 1.41098697, 2.32238772, 0.83290912, 0.64185389, 1.25276297, 1.74046617, 1.48160454, 1.38629436, 0.33647224, 1.45861502, -0.10536052, ... 1.80828877, 1.09861229, 1.91692261, 2.96527307, 1.41098697, 1.79175947, 2.20827441, 2.14006616, 0.18232156, 1.16315081, 2.4510051 , 2.27212589, 1.09861229, -0.22314355, 1.19392247, 1.56861592, 1.58923521, -0.69314718, 2.24070969, 0.58778666, 0. , 2.3321439 , 2.05412373, 0.83290912, 1.88706965, 2.50959926, 1.54756251, 1.84054963, 1.88706965, 1.06471074, 0.69314718, 0.26236426, 0.91629073, 0.09531018, 0.26236426, 0.53062825, -0.10536052, 0.58778666, 1.56861592, 0.58778666, 1.22377543, -0.10536052, 2.29253476, 1.68639895, 2.1517622 , 0.69314718, 1.90210753, 1.36097655, 1.79175947, 1.60943791, 0.95551145, 2.37954613, 0.91629073, 0.78845736, 1.56861592, 1.33500107, 2.60268969, 1.09861229, 1.48160454, 1.36097655, 0.64185389, 0.47000363, 0.64185389, 0.33647224, 1.90210753, 3.02042489, 1.80828877, 2.63188884, 2.3321439 , 1.75785792, 2.24070969, 1.25276297, 1.43508453, 2.45958884, 1.98787435, 1.56861592, 0.64185389, -0.22314355, 1.56861592, 2.3321439 , 2.43361336, 2.04122033, 2.4765384 , -0.51082562, 1.91692261, 1.68639895, 1.16315081, 0.78845736, 2.00148 , 1.64865863, 0.83290912, 0.87546874, 2.77258872, 2.2617631 , 1.87180218, 1.5260563 , 1.62924054, 1.33500107, 1.09861229])
- created_at :
- 2020-09-06T15:12:24.654109
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (obs_id: 919) Coordinates: * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 ... 911 912 913 914 915 916 917 918 Data variables: y (obs_id) float64 0.8329 0.8329 1.099 0.09531 ... 1.629 1.335 1.099 Attributes: created_at: 2020-09-06T15:12:24.654109 arviz_version: 0.9.0xarray.Dataset
We now want to calculate the highest density interval given by the posterior predictive on Radon levels. However, we are not interested in the HDI of each observation but in the HDI of each level (either Basement or First Floor). We first group posterior_predictive samples using coords and then pass the specific dimensions ("chain", "draw", "obs_id") to az.hdi.
floor = xr.DataArray(floor, dims=("obs_id"))
hdi_helper = lambda ds: az.hdi(ds, input_core_dims=[["chain", "draw", "obs_id"]])
hdi_ppc = posterior_predictive.posterior_predictive["y"].groupby(floor).apply(hdi_helper)["y"]
hdi_ppc
<xarray.DataArray 'y' (group: 2, hdi: 2)>
array([[-0.12597895, 2.84736681],
[-0.7139045 , 2.26243448]])
Coordinates:
* hdi (hdi) <U6 'lower' 'higher'
* group (group) int64 0 1- group: 2
- hdi: 2
- -0.126 2.847 -0.7139 2.262
array([[-0.12597895, 2.84736681], [-0.7139045 , 2.26243448]]) - hdi(hdi)<U6'lower' 'higher'
- hdi_prob :
- 0.94
array(['lower', 'higher'], dtype='<U6')
- group(group)int640 1
array([0, 1])
In addition, ArviZ has also included the hdi_prob as an attribute of the hdi coordinate, click on its file icon to see it!
We will now add one extra coordinate to the observed_data group: the Level labels (not indices). This will allow xarray to automatically generate the correct xlabel and xticklabels so we don’t have to worry about labeling too much. In this particular case we will only do one plot, which makes the adding of a coordinate a bit of an overkill. In many cases however, we will have several plots and using this approach will automate labeling for all plots. Eventually, we will sort by Level coordinate to make sure Basement is the first value and goes at the left of the plot.
posterior_predictive.rename(name_dict={"a_dim_0": "Level"}, inplace=True)
posterior_predictive.assign_coords({"Level": ["Basement", "First Floor"]}, inplace=True)
level_labels = posterior_predictive.posterior.Level[floor]
posterior_predictive.observed_data = posterior_predictive.observed_data.assign_coords(Level=level_labels).sortby("Level")
Plot the point estimates of the slope and intercept for the complete pooling model.
xvals = xr.DataArray([0, 1], dims="Level", coords={"Level": ["Basement", "First Floor"]})
posterior_predictive.posterior["a"] = posterior_predictive.posterior.a[:, :, 0] + posterior_predictive.posterior.a[:, :, 1] * xvals
pooled_means = posterior_predictive.posterior.mean(dim=("chain", "draw"))
_, ax = plt.subplots()
posterior_predictive.observed_data.plot.scatter(x="Level", y="y", label="Observations", alpha=0.4, ax=ax)
az.plot_hdi(
[0, 1], hdi_data=hdi_ppc, fill_kwargs={"alpha": 0.2, "label": "Exp. distrib. of Radon levels"}, ax=ax
)
az.plot_hdi(
[0, 1], posterior_predictive.posterior.a, fill_kwargs={"alpha": 0.5, "label": "Exp. mean HPD"}, ax=ax
)
ax.plot([0, 1], pooled_means.a, label="Exp. mean")
ax.set_ylabel("Log radon level")
ax.legend(ncol=2, fontsize=9, frameon=True);

The 94% interval of the expected value is very narrow, and even narrower for basement measurements, meaning that the model is slightly more confident about these observations. The sampling distribution of individual radon levels is much wider. We can infer that floor level does account for some of the variation in radon levels. We can see however that the model underestimates the dispersion in radon levels across households – lots of them lie outside the light orange prediction envelope. Also, the error rates are high representing high bias. So this model is a good start but we can’t stop there.
No pooling:¶
Here we do not pool the estimates of the intercepts but completely pool the slope estimates assuming the variance is same within each county. $$ y_i = \alpha_{j[i]} + \beta x_i + \epsilon_i $$ where $j$ = 1, ..., 85 representing each county.
@pm.model
def unpooled_model():
a_county = yield pm.Normal('a_county', loc=0., scale=10., batch_stack=counties)
beta = yield pm.Normal('beta', loc=0, scale=10.)
loc = tf.gather(a_county, county_idx) + beta*floor
scale = yield pm.Exponential("sigma", rate=1.)
y = yield pm.Normal('y', loc=loc, scale=scale, observed=data.log_radon.values)
unpooled_advi = pm.fit(unpooled_model(), num_steps=25_000)
plot_elbo(unpooled_advi.losses)
|>>>>>>>>>>>>>>>>>>>>|

unpooled_advi_samples = unpooled_advi.approximation.sample(2_000)
remove_scope(unpooled_advi_samples)
unpooled_advi_samples
-
- a_county_dim_0: 85
- chain: 1
- draw: 2000
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- a_county_dim_0(a_county_dim_0)int640 1 2 3 4 5 6 ... 79 80 81 82 83 84
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84])
- a_county(chain, draw, a_county_dim_0)float320.36999083 1.0238843 ... 1.0384322
array([[[0.36999083, 1.0238843 , 2.0252652 , ..., 2.034409 , 1.578296 , 0.9983911 ], [0.64774776, 0.91157115, 1.2923429 , ..., 2.0109618 , 1.6982571 , 0.8811697 ], [1.8972617 , 0.9602209 , 1.4117332 , ..., 1.5687102 , 1.779839 , 1.200284 ], ..., [0.7107576 , 0.82900226, 2.0056863 , ..., 1.8268906 , 1.7657291 , 0.28820467], [1.2736075 , 1.03682 , 1.1554356 , ..., 1.5688866 , 1.4610525 , 1.1454637 ], [0.3937166 , 0.88760495, 1.3843511 , ..., 1.773532 , 1.7758514 , 1.0384322 ]]], dtype=float32) - beta(chain, draw)float32-0.56419456 ... -0.6635491
array([[-0.56419456, -0.76161397, -0.6025331 , ..., -0.7432619 , -0.65681094, -0.6635491 ]], dtype=float32) - __log_sigma(chain, draw)float32-0.28598142 ... -0.3346977
array([[-0.28598142, -0.28851208, -0.29483494, ..., -0.331497 , -0.2910944 , -0.3346977 ]], dtype=float32) - sigma(chain, draw)float320.7512766 0.7493777 ... 0.71555436
array([[0.7512766 , 0.7493777 , 0.7446545 , ..., 0.7178483 , 0.7474451 , 0.71555436]], dtype=float32)
- created_at :
- 2020-09-06T15:12:43.221131
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (a_county_dim_0: 85, chain: 1, draw: 2000) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 6 ... 1994 1995 1996 1997 1998 1999 * a_county_dim_0 (a_county_dim_0) int64 0 1 2 3 4 5 6 ... 79 80 81 82 83 84 Data variables: a_county (chain, draw, a_county_dim_0) float32 0.36999083 ... 1.03... beta (chain, draw) float32 -0.56419456 -0.76161397 ... -0.6635491 __log_sigma (chain, draw) float32 -0.28598142 -0.28851208 ... -0.3346977 sigma (chain, draw) float32 0.7512766 0.7493777 ... 0.71555436 Attributes: created_at: 2020-09-06T15:12:43.221131 arviz_version: 0.9.0xarray.Dataset -
- obs_id: 919
- obs_id(obs_id)int640 1 2 3 4 5 ... 914 915 916 917 918
array([ 0, 1, 2, ..., 916, 917, 918])
- y(obs_id)float640.8329 0.8329 1.099 ... 1.335 1.099
array([ 0.83290912, 0.83290912, 1.09861229, 0.09531018, 1.16315081, 0.95551145, 0.47000363, 0.09531018, -0.22314355, 0.26236426, 0.26236426, 0.33647224, 0.40546511, -0.69314718, 0.18232156, 1.5260563 , 0.33647224, 0.78845736, 1.79175947, 1.22377543, 0.64185389, 1.70474809, 1.85629799, 0.69314718, 1.90210753, 1.16315081, 1.93152141, 1.96009478, 2.05412373, 1.66770682, 1.5260563 , 1.5040774 , 1.06471074, 2.10413415, 0.53062825, 1.45861502, 1.70474809, 1.41098697, 0.87546874, 1.09861229, 0.40546511, 1.22377543, 1.09861229, 0.64185389, -1.2039728 , 0.91629073, 0.18232156, 0.83290912, -0.35667494, 0.58778666, 1.09861229, 0.83290912, 0.58778666, 0.40546511, 0.69314718, 0.64185389, 0.26236426, 1.48160454, 1.5260563 , 1.85629799, 1.54756251, 1.75785792, 0.83290912, -0.69314718, 1.54756251, 1.5040774 , 1.90210753, 1.02961942, 1.09861229, 1.09861229, 1.98787435, 1.62924054, 0.99325177, 1.62924054, 2.57261223, 1.98787435, 1.93152141, 2.55722731, 1.77495235, 2.2617631 , 1.80828877, 1.36097655, 2.66722821, 0.64185389, 1.94591015, 1.56861592, 2.2617631 , 0.95551145, 1.91692261, 1.41098697, 2.32238772, 0.83290912, 0.64185389, 1.25276297, 1.74046617, 1.48160454, 1.38629436, 0.33647224, 1.45861502, -0.10536052, ... 1.80828877, 1.09861229, 1.91692261, 2.96527307, 1.41098697, 1.79175947, 2.20827441, 2.14006616, 0.18232156, 1.16315081, 2.4510051 , 2.27212589, 1.09861229, -0.22314355, 1.19392247, 1.56861592, 1.58923521, -0.69314718, 2.24070969, 0.58778666, 0. , 2.3321439 , 2.05412373, 0.83290912, 1.88706965, 2.50959926, 1.54756251, 1.84054963, 1.88706965, 1.06471074, 0.69314718, 0.26236426, 0.91629073, 0.09531018, 0.26236426, 0.53062825, -0.10536052, 0.58778666, 1.56861592, 0.58778666, 1.22377543, -0.10536052, 2.29253476, 1.68639895, 2.1517622 , 0.69314718, 1.90210753, 1.36097655, 1.79175947, 1.60943791, 0.95551145, 2.37954613, 0.91629073, 0.78845736, 1.56861592, 1.33500107, 2.60268969, 1.09861229, 1.48160454, 1.36097655, 0.64185389, 0.47000363, 0.64185389, 0.33647224, 1.90210753, 3.02042489, 1.80828877, 2.63188884, 2.3321439 , 1.75785792, 2.24070969, 1.25276297, 1.43508453, 2.45958884, 1.98787435, 1.56861592, 0.64185389, -0.22314355, 1.56861592, 2.3321439 , 2.43361336, 2.04122033, 2.4765384 , -0.51082562, 1.91692261, 1.68639895, 1.16315081, 0.78845736, 2.00148 , 1.64865863, 0.83290912, 0.87546874, 2.77258872, 2.2617631 , 1.87180218, 1.5260563 , 1.62924054, 1.33500107, 1.09861229])
- created_at :
- 2020-09-06T15:12:43.223073
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (obs_id: 919) Coordinates: * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 ... 911 912 913 914 915 916 917 918 Data variables: y (obs_id) float64 0.8329 0.8329 1.099 0.09531 ... 1.629 1.335 1.099 Attributes: created_at: 2020-09-06T15:12:43.223073 arviz_version: 0.9.0xarray.Dataset
Let’s plot each county's expected values with 94% confidence interval.
unpooled_advi_samples.assign_coords(coords={"a_county_dim_0": mn_counties}, inplace=True)
az.plot_forest(
unpooled_advi_samples, var_names="a_county", figsize=(6, 16), combined=True, textsize=8
);

Looking at the counties all together, the unpooling analysis overfits the data within each county. Also giving a view that individual counties look more different than they actually are.
Since we are modelling data within each county, we can plot the ordered mean estimates to identify counties with high radon levels.
unpooled_means = unpooled_advi_samples.posterior.mean(dim=("chain", "draw"))
unpooled_hdi = az.hdi(unpooled_advi_samples)
We will now take advantage of label based indexing for Datasets with the sel method and of automagical sorting capabilities. We first sort using the values of a specific 1D variable a. Then, thanks to unpooled_means and unpooled_hdi both having the a_county_dim_0 (representing each county) dimension, we can pass a 1D DataArray to sort the second dataset too.
fig, ax = plt.subplots(figsize=(7, 5))
xticks = np.arange(0, 86, 6)
fontdict = {"horizontalalignment": "right", "fontsize": 10}
unpooled_means_iter = unpooled_means.sortby("a_county")
unpooled_hdi_iter = unpooled_hdi.sortby(unpooled_means_iter["a_county"])
unpooled_means_iter.plot.scatter(x=f"a_county_dim_0", y="a_county", ax=ax, alpha=0.8)
ax.vlines(
np.arange(counties),
unpooled_hdi_iter["a_county"].sel(hdi="lower"),
unpooled_hdi_iter["a_county"].sel(hdi="higher"),
color="orange", alpha=0.6
)
ax.set(
ylabel="Radon estimate",
xlabel="Ordered County",
ylim=(-1, 4.5),
xticks=xticks
)
ax.set_xticklabels(unpooled_means_iter[f"a_county_dim_0"].values[xticks], fontdict=fontdict)
ax.tick_params(rotation=30)

Here are some visual comparisons between the pooled and unpooled estimates for a subset of counties representing a range of sample sizes.
SAMPLE_COUNTIES = (
"LAC QUI PARLE",
"AITKIN",
"KOOCHICHING",
"DOUGLAS",
"CLAY",
"STEARNS",
"RAMSEY",
"ST LOUIS",
)
unpooled_advi_samples.observed_data = unpooled_advi_samples.observed_data.assign_coords({
"County": ("obs_id", mn_counties[county_idx]),
"Level": ("obs_id", np.array(["Basement", "Floor"])[floor.values.astype(np.int32)])
})
fig, axes = plt.subplots(2, 4, figsize=(12, 6), sharey=True, sharex=True)
xspace = np.linspace(0, 1, 100)
for ax, c in zip(axes.ravel(), SAMPLE_COUNTIES):
sample_county_mask = unpooled_advi_samples.observed_data.County.isin([c])
# plot obs:
unpooled_advi_samples.observed_data.where(
sample_county_mask, drop=True
).sortby("Level").plot.scatter(x="Level", y="y", ax=ax, alpha=.4, label="Log Radon")
# plot both models:
ax.plot([0, 1], unpooled_means.a_county.sel(a_county_dim_0=c) + unpooled_means.beta*xvals, "b", label="Unpooled estimates")
ax.plot([0, 1], pooled_means.a, "r--", label="Pooled estimates")
ax.set_title(c); ax.set_xlabel(""); ax.set_ylabel("")
ax.tick_params(labelsize=10)
axes[0,0].set_ylabel("Log radon level"); axes[1,0].set_ylabel("Log radon level")
axes[0,0].legend(fontsize=8, frameon=True); axes[1,0].legend(fontsize=8, frameon=True);

Notice the slopes $\beta$ differ slightly. The county LAC QUI PARLE has the highest average radon level from 85 counties as it is evident from the previous plot. But these estimates are calculated with just two observations. And there is a big shift in its intercept from complete pooling to no pooling. This is a classic issue with no-pooling models: when you estimate clusters independently from each other, can you trust estimates from small-sample-size counties?
Neither of these models are satisfactory:
- If we are trying to identify high-radon counties, pooling is not useful as it ignores any variation in average radon levels between counties.
- We do not trust extreme unpooled estimates produced by models using few observations. This leads to maximal overfitting: only the within-county variations are taken into account and the overall population is not estimated.
Multilevel and hierarchical models¶
When we pool our data, we imply that they are sampled from the same model. This ignores any variation among sampling units (other than sampling variance) -- we assume that counties are all the same:
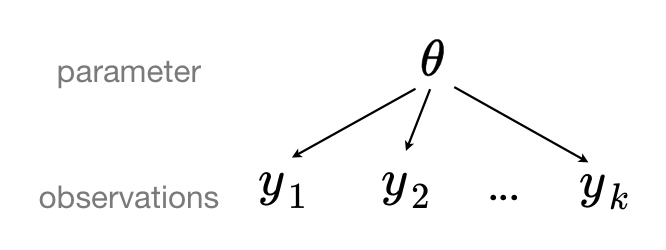
When we analyze data unpooled, we imply that they are sampled independently from separate models. At the opposite extreme from the pooled case, this approach claims that differences between sampling units are too large to combine them -- we assume that counties have no similarity whatsoever:
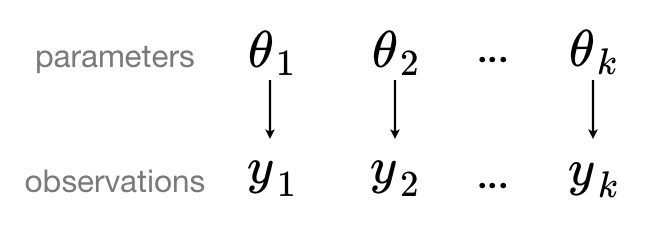
In a hierarchical model, parameters are viewed as a sample from a population distribution of parameters. Thus, we view them as being neither entirely different or exactly the same. This is partial pooling:
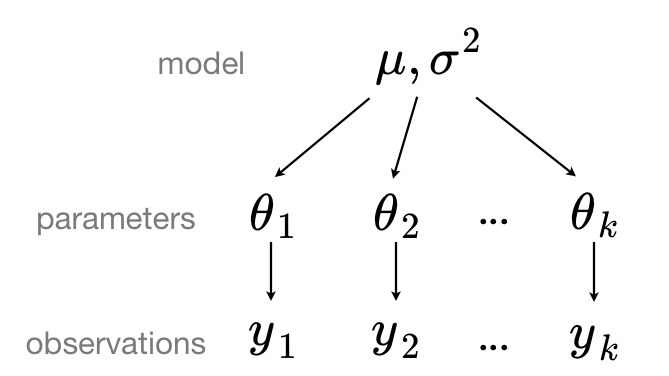
We can use PyMC to easily specify multilevel models, and fit them using Variational Inference Approximations.
Partial pooling model¶
The simplest partial pooling model for the household radon dataset is one which simply estimates radon levels, without any predictors at any level. A partial pooling model represents a compromise between the pooled and unpooled extremes, approximately a weighted average (based on sample size) of the unpooled county estimates and the pooled estimates.
$$\hat{\alpha} \approx \frac{(n_j/\sigma_y^2)\bar{y}_j + (1/\sigma_{\alpha}^2)\bar{y}}{(n_j/\sigma_y^2) + (1/\sigma_{\alpha}^2)}$$ where $n_j$ is the number of houses for county $j$, $\sigma_y^{2}$ is within county variance, and $\sigma_a^{2}$ is the variance among the average log radon levels of the different counties.
We expect the following when using partial pooling:
- Estimates for counties with smaller sample sizes will shrink towards the state-wide average.
- Estimates for counties with larger sample sizes will be closer to the unpooled county estimates and will influence the the state-wide average.
@pm.model
def partial_pooling():
# Priors
mu_a = yield pm.Normal('mu_a', loc=0., scale=10.)
sigma_a = yield pm.HalfCauchy('sigma_a', scale=1.)
# Intercepts
a_county = yield pm.Normal('a_county', loc=mu_a, scale=sigma_a, batch_stack=counties)
loc = tf.gather(a_county, county_idx)
scale = yield pm.Exponential("sigma", rate=1.)
y = yield pm.Normal('y', loc=loc, scale=scale, observed=data.log_radon.values)
partial_pooling_advi = pm.fit(partial_pooling(), num_steps=25_000)
plot_elbo(partial_pooling_advi.losses)
|>>>>>>>>>>>>>>>>>>>>|

partial_pooling_samples = partial_pooling_advi.approximation.sample(2_000)
remove_scope(partial_pooling_samples)
partial_pooling_samples
-
- a_county_dim_0: 85
- chain: 1
- draw: 2000
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- a_county_dim_0(a_county_dim_0)int640 1 2 3 4 5 6 ... 79 80 81 82 83 84
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84])
- mu_a(chain, draw)float321.3184162 1.3072621 ... 1.3369763
array([[1.3184162, 1.3072621, 1.3651627, ..., 1.3594881, 1.3647654, 1.3369763]], dtype=float32) - a_county(chain, draw, a_county_dim_0)float321.1006255 0.82927036 ... 1.4069959
array([[[1.1006255 , 0.82927036, 1.0694137 , ..., 1.3657898 , 1.660825 , 1.4485801 ], [0.99680126, 0.7985607 , 0.7317189 , ..., 1.5842866 , 1.6412865 , 1.2769667 ], [1.1700957 , 1.1524378 , 1.4914379 , ..., 1.426831 , 1.7535654 , 0.9966372 ], ..., [0.7133796 , 0.9491382 , 0.80141616, ..., 1.4381852 , 1.3584955 , 1.4065135 ], [1.0746276 , 0.94761926, 1.1560918 , ..., 1.6516389 , 1.5542179 , 1.3733586 ], [1.423568 , 1.0943595 , 1.0630486 , ..., 1.6526098 , 1.5484184 , 1.4069959 ]]], dtype=float32) - __log_sigma_a(chain, draw)float32-1.1094719 ... -1.1693175
array([[-1.1094719, -1.1404127, -1.050507 , ..., -1.1475506, -1.2099934, -1.1693175]], dtype=float32) - __log_sigma(chain, draw)float32-0.2506265 ... -0.28390348
array([[-0.2506265 , -0.25947058, -0.2589428 , ..., -0.26138023, -0.2666051 , -0.28390348]], dtype=float32) - sigma_a(chain, draw)float320.32973304 ... 0.31057885
array([[0.32973304, 0.31968707, 0.3497604 , ..., 0.3174133 , 0.29819927, 0.31057885]], dtype=float32) - sigma(chain, draw)float320.77831304 0.77145994 ... 0.7528393
array([[0.77831304, 0.77145994, 0.77186716, ..., 0.76998806, 0.7659755 , 0.7528393 ]], dtype=float32)
- created_at :
- 2020-09-06T15:13:08.869424
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (a_county_dim_0: 85, chain: 1, draw: 2000) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 6 ... 1994 1995 1996 1997 1998 1999 * a_county_dim_0 (a_county_dim_0) int64 0 1 2 3 4 5 6 ... 79 80 81 82 83 84 Data variables: mu_a (chain, draw) float32 1.3184162 1.3072621 ... 1.3369763 a_county (chain, draw, a_county_dim_0) float32 1.1006255 ... 1.406... __log_sigma_a (chain, draw) float32 -1.1094719 -1.1404127 ... -1.1693175 __log_sigma (chain, draw) float32 -0.2506265 -0.25947058 ... -0.28390348 sigma_a (chain, draw) float32 0.32973304 0.31968707 ... 0.31057885 sigma (chain, draw) float32 0.77831304 0.77145994 ... 0.7528393 Attributes: created_at: 2020-09-06T15:13:08.869424 arviz_version: 0.9.0xarray.Dataset -
- obs_id: 919
- obs_id(obs_id)int640 1 2 3 4 5 ... 914 915 916 917 918
array([ 0, 1, 2, ..., 916, 917, 918])
- y(obs_id)float640.8329 0.8329 1.099 ... 1.335 1.099
array([ 0.83290912, 0.83290912, 1.09861229, 0.09531018, 1.16315081, 0.95551145, 0.47000363, 0.09531018, -0.22314355, 0.26236426, 0.26236426, 0.33647224, 0.40546511, -0.69314718, 0.18232156, 1.5260563 , 0.33647224, 0.78845736, 1.79175947, 1.22377543, 0.64185389, 1.70474809, 1.85629799, 0.69314718, 1.90210753, 1.16315081, 1.93152141, 1.96009478, 2.05412373, 1.66770682, 1.5260563 , 1.5040774 , 1.06471074, 2.10413415, 0.53062825, 1.45861502, 1.70474809, 1.41098697, 0.87546874, 1.09861229, 0.40546511, 1.22377543, 1.09861229, 0.64185389, -1.2039728 , 0.91629073, 0.18232156, 0.83290912, -0.35667494, 0.58778666, 1.09861229, 0.83290912, 0.58778666, 0.40546511, 0.69314718, 0.64185389, 0.26236426, 1.48160454, 1.5260563 , 1.85629799, 1.54756251, 1.75785792, 0.83290912, -0.69314718, 1.54756251, 1.5040774 , 1.90210753, 1.02961942, 1.09861229, 1.09861229, 1.98787435, 1.62924054, 0.99325177, 1.62924054, 2.57261223, 1.98787435, 1.93152141, 2.55722731, 1.77495235, 2.2617631 , 1.80828877, 1.36097655, 2.66722821, 0.64185389, 1.94591015, 1.56861592, 2.2617631 , 0.95551145, 1.91692261, 1.41098697, 2.32238772, 0.83290912, 0.64185389, 1.25276297, 1.74046617, 1.48160454, 1.38629436, 0.33647224, 1.45861502, -0.10536052, ... 1.80828877, 1.09861229, 1.91692261, 2.96527307, 1.41098697, 1.79175947, 2.20827441, 2.14006616, 0.18232156, 1.16315081, 2.4510051 , 2.27212589, 1.09861229, -0.22314355, 1.19392247, 1.56861592, 1.58923521, -0.69314718, 2.24070969, 0.58778666, 0. , 2.3321439 , 2.05412373, 0.83290912, 1.88706965, 2.50959926, 1.54756251, 1.84054963, 1.88706965, 1.06471074, 0.69314718, 0.26236426, 0.91629073, 0.09531018, 0.26236426, 0.53062825, -0.10536052, 0.58778666, 1.56861592, 0.58778666, 1.22377543, -0.10536052, 2.29253476, 1.68639895, 2.1517622 , 0.69314718, 1.90210753, 1.36097655, 1.79175947, 1.60943791, 0.95551145, 2.37954613, 0.91629073, 0.78845736, 1.56861592, 1.33500107, 2.60268969, 1.09861229, 1.48160454, 1.36097655, 0.64185389, 0.47000363, 0.64185389, 0.33647224, 1.90210753, 3.02042489, 1.80828877, 2.63188884, 2.3321439 , 1.75785792, 2.24070969, 1.25276297, 1.43508453, 2.45958884, 1.98787435, 1.56861592, 0.64185389, -0.22314355, 1.56861592, 2.3321439 , 2.43361336, 2.04122033, 2.4765384 , -0.51082562, 1.91692261, 1.68639895, 1.16315081, 0.78845736, 2.00148 , 1.64865863, 0.83290912, 0.87546874, 2.77258872, 2.2617631 , 1.87180218, 1.5260563 , 1.62924054, 1.33500107, 1.09861229])
- created_at :
- 2020-09-06T15:13:08.875350
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (obs_id: 919) Coordinates: * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 ... 911 912 913 914 915 916 917 918 Data variables: y (obs_id) float64 0.8329 0.8329 1.099 0.09531 ... 1.629 1.335 1.099 Attributes: created_at: 2020-09-06T15:13:08.875350 arviz_version: 0.9.0xarray.Dataset
To compare partial-pooling and no-pooling estimates, let’s run the unpooled model without the floor predictor:
@pm.model
def unpooled_without_floor():
a_county = yield pm.Normal('a_county', loc=0., scale=10., batch_stack=counties)
loc = tf.gather(a_county, county_idx)
scale = yield pm.Exponential("sigma", rate=1.)
y = yield pm.Normal('y', loc=loc, scale=scale, observed=data.log_radon.values)
unpooled_without_floor_advi = pm.fit(unpooled_without_floor(), num_steps=25_000)
plot_elbo(unpooled_without_floor_advi.losses)
|>>>>>>>>>>>>>>>>>>>>|

unpooled_without_floor_samples = unpooled_without_floor_advi.approximation.sample(2_000)
remove_scope(unpooled_without_floor_samples)
unpooled_without_floor_samples
-
- a_county_dim_0: 85
- chain: 1
- draw: 2000
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- a_county_dim_0(a_county_dim_0)int640 1 2 3 4 5 6 ... 79 80 81 82 83 84
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84])
- a_county(chain, draw, a_county_dim_0)float321.0178491 1.0013496 ... 1.4488665
array([[[1.0178491 , 1.0013496 , 0.49264288, ..., 1.4281553 , 1.5073564 , 1.8631239 ], [0.26082283, 0.91135824, 0.62953234, ..., 1.5972172 , 1.5199922 , 1.0201625 ], [0.58227336, 0.9683933 , 1.0847672 , ..., 1.347017 , 1.7169664 , 1.1955161 ], ..., [0.7516582 , 0.81360966, 0.87281895, ..., 1.5931329 , 1.724778 , 0.7069099 ], [0.7011503 , 0.7636232 , 1.5743186 , ..., 1.432193 , 1.4250641 , 0.9046785 ], [0.95084935, 0.7369791 , 1.8440148 , ..., 1.5269847 , 1.6424592 , 1.4488665 ]]], dtype=float32) - __log_sigma(chain, draw)float32-0.13307804 ... -0.24015264
array([[-0.13307804, -0.2458005 , -0.20709029, ..., -0.15590635, -0.25564823, -0.24015264]], dtype=float32) - sigma(chain, draw)float320.8753968 0.78207827 ... 0.7865078
array([[0.8753968 , 0.78207827, 0.81294626, ..., 0.85563934, 0.7744143 , 0.7865078 ]], dtype=float32)
- created_at :
- 2020-09-06T15:13:25.786248
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (a_county_dim_0: 85, chain: 1, draw: 2000) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 6 ... 1994 1995 1996 1997 1998 1999 * a_county_dim_0 (a_county_dim_0) int64 0 1 2 3 4 5 6 ... 79 80 81 82 83 84 Data variables: a_county (chain, draw, a_county_dim_0) float32 1.0178491 ... 1.448... __log_sigma (chain, draw) float32 -0.13307804 -0.2458005 ... -0.24015264 sigma (chain, draw) float32 0.8753968 0.78207827 ... 0.7865078 Attributes: created_at: 2020-09-06T15:13:25.786248 arviz_version: 0.9.0xarray.Dataset -
- obs_id: 919
- obs_id(obs_id)int640 1 2 3 4 5 ... 914 915 916 917 918
array([ 0, 1, 2, ..., 916, 917, 918])
- y(obs_id)float640.8329 0.8329 1.099 ... 1.335 1.099
array([ 0.83290912, 0.83290912, 1.09861229, 0.09531018, 1.16315081, 0.95551145, 0.47000363, 0.09531018, -0.22314355, 0.26236426, 0.26236426, 0.33647224, 0.40546511, -0.69314718, 0.18232156, 1.5260563 , 0.33647224, 0.78845736, 1.79175947, 1.22377543, 0.64185389, 1.70474809, 1.85629799, 0.69314718, 1.90210753, 1.16315081, 1.93152141, 1.96009478, 2.05412373, 1.66770682, 1.5260563 , 1.5040774 , 1.06471074, 2.10413415, 0.53062825, 1.45861502, 1.70474809, 1.41098697, 0.87546874, 1.09861229, 0.40546511, 1.22377543, 1.09861229, 0.64185389, -1.2039728 , 0.91629073, 0.18232156, 0.83290912, -0.35667494, 0.58778666, 1.09861229, 0.83290912, 0.58778666, 0.40546511, 0.69314718, 0.64185389, 0.26236426, 1.48160454, 1.5260563 , 1.85629799, 1.54756251, 1.75785792, 0.83290912, -0.69314718, 1.54756251, 1.5040774 , 1.90210753, 1.02961942, 1.09861229, 1.09861229, 1.98787435, 1.62924054, 0.99325177, 1.62924054, 2.57261223, 1.98787435, 1.93152141, 2.55722731, 1.77495235, 2.2617631 , 1.80828877, 1.36097655, 2.66722821, 0.64185389, 1.94591015, 1.56861592, 2.2617631 , 0.95551145, 1.91692261, 1.41098697, 2.32238772, 0.83290912, 0.64185389, 1.25276297, 1.74046617, 1.48160454, 1.38629436, 0.33647224, 1.45861502, -0.10536052, ... 1.80828877, 1.09861229, 1.91692261, 2.96527307, 1.41098697, 1.79175947, 2.20827441, 2.14006616, 0.18232156, 1.16315081, 2.4510051 , 2.27212589, 1.09861229, -0.22314355, 1.19392247, 1.56861592, 1.58923521, -0.69314718, 2.24070969, 0.58778666, 0. , 2.3321439 , 2.05412373, 0.83290912, 1.88706965, 2.50959926, 1.54756251, 1.84054963, 1.88706965, 1.06471074, 0.69314718, 0.26236426, 0.91629073, 0.09531018, 0.26236426, 0.53062825, -0.10536052, 0.58778666, 1.56861592, 0.58778666, 1.22377543, -0.10536052, 2.29253476, 1.68639895, 2.1517622 , 0.69314718, 1.90210753, 1.36097655, 1.79175947, 1.60943791, 0.95551145, 2.37954613, 0.91629073, 0.78845736, 1.56861592, 1.33500107, 2.60268969, 1.09861229, 1.48160454, 1.36097655, 0.64185389, 0.47000363, 0.64185389, 0.33647224, 1.90210753, 3.02042489, 1.80828877, 2.63188884, 2.3321439 , 1.75785792, 2.24070969, 1.25276297, 1.43508453, 2.45958884, 1.98787435, 1.56861592, 0.64185389, -0.22314355, 1.56861592, 2.3321439 , 2.43361336, 2.04122033, 2.4765384 , -0.51082562, 1.91692261, 1.68639895, 1.16315081, 0.78845736, 2.00148 , 1.64865863, 0.83290912, 0.87546874, 2.77258872, 2.2617631 , 1.87180218, 1.5260563 , 1.62924054, 1.33500107, 1.09861229])
- created_at :
- 2020-09-06T15:13:25.787835
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (obs_id: 919) Coordinates: * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 ... 911 912 913 914 915 916 917 918 Data variables: y (obs_id) float64 0.8329 0.8329 1.099 0.09531 ... 1.629 1.335 1.099 Attributes: created_at: 2020-09-06T15:13:25.787835 arviz_version: 0.9.0xarray.Dataset
Now let’s compare both models’ estimates for all 85 counties. We’ll plot the estimates against each county’s sample size, to let you see more clearly what hierarchical models bring to the table:
N_county = data.groupby("county")["idnum"].count().values
fig, axes = plt.subplots(1, 2, figsize=(10, 4), sharex=True, sharey=True)
for ax, idata, func_name, level in zip(
axes,
(unpooled_without_floor_samples, partial_pooling_samples),
(unpooled_without_floor().name, partial_pooling().name),
("no pooling", "partial pooling"),
):
# add variable with x values to xarray dataset
idata.posterior = idata.posterior.assign_coords({"N_county": ("a_county_dim_0", N_county)})
# plot means
idata.posterior.mean(dim=("chain", "draw")).plot.scatter(x="N_county", y="a_county", ax=ax, alpha=0.9);
ax.hlines(
partial_pooling_samples.posterior.a_county.mean(),
0.9,
max(N_county) + 1,
alpha=0.4,
ls="--",
label="Est. population mean",
)
# plot hdi
hdi = az.hdi(idata).a_county
ax.vlines(N_county, hdi.sel(hdi="lower"), hdi.sel(hdi="higher"), color="orange", alpha=0.5)
ax.set(
title=f"{level.title()} Estimates",
xlabel="Nbr obs in county (log scale)",
xscale="log",
ylabel="Log radon Level",
)
ax.legend(fontsize=10)

Notice the difference between the unpooled and partially-pooled estimates, particularly at smaller sample sizes: As expected, the former is both more extreme and more imprecise. Indeed, in the partially-pooled model, estimates in small-sample-size counties are informed by the population parameters – hence more precise estimates. Moreover, the smaller the sample size, the more regression towards the overall mean (the dashed gray line) – hence less extreme estimates. In other words, the model is skeptical of extreme deviations from the population mean in counties where data is sparse.
Now let’s try to integrate the floor predictor -
Varying intercept model¶
As above, this model allows intercepts to vary across county, according to a random effect. We just add a fixed slope for the predictor (i.e all counties will have the same slope):
$$y_i = \alpha_{j[i]} + \beta x_{i} + \epsilon_i$$
where
$$\epsilon_i \sim N(0, \sigma_y^2)$$
and the intercept random effect:
$$\alpha_{j[i]} \sim N(\mu_{\alpha}, \sigma_{\alpha}^2)$$
As with the the no-pooling model, we set a separate intercept for each county, but rather than fitting separate regression models for each county, multilevel modeling shares strength among counties, allowing for more reasonable inference in counties with little data. Here is what that looks in code:
@pm.model
def varying_intercept():
mu_a = yield pm.Normal('mu_a', loc=0., scale=1e5)
sigma_a = yield pm.HalfCauchy('sigma_a', scale=5.)
a_county = yield pm.Normal('a_county', loc=mu_a, scale=sigma_a, batch_stack=counties)
b = yield pm.Normal('b', loc=0., scale=10.)
loc = tf.gather(a_county, county_idx) + b*floor
scale = yield pm.Exponential("sigma", rate=1.)
y = yield pm.Normal('y', loc=loc, scale=scale, observed=data.log_radon.values)
varying_intercept_advi = pm.fit(varying_intercept(), num_steps=40_000)
plot_elbo(varying_intercept_advi.losses)
|>>>>>>>>>>>>>>>>>>>>|

varying_intercept_samples = varying_intercept_advi.approximation.sample(2_000)
remove_scope(varying_intercept_samples)
varying_intercept_samples
-
- a_county_dim_0: 85
- chain: 1
- draw: 2000
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- a_county_dim_0(a_county_dim_0)int640 1 2 3 4 5 6 ... 79 80 81 82 83 84
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84])
- mu_a(chain, draw)float321.4493645 1.5067779 ... 1.5112383
array([[1.4493645, 1.5067779, 1.4653704, ..., 1.4295348, 1.5160272, 1.5112383]], dtype=float32) - a_county(chain, draw, a_county_dim_0)float321.782057 1.1568834 ... 1.7976772
array([[[1.782057 , 1.1568834 , 1.1844532 , ..., 1.7383634 , 1.8035787 , 1.6306922 ], [1.2556518 , 0.90442353, 1.6552949 , ..., 1.5384247 , 1.7612361 , 1.743976 ], [0.8760731 , 0.8613335 , 2.2567198 , ..., 1.5762341 , 1.5510461 , 1.8853244 ], ..., [1.1741817 , 0.95642495, 1.7446842 , ..., 1.5429543 , 1.4440159 , 1.1208017 ], [1.3757881 , 0.87958705, 1.3585677 , ..., 1.6110898 , 1.7152646 , 0.9002575 ], [1.2784272 , 1.0408564 , 1.6897631 , ..., 1.472668 , 1.6169112 , 1.7976772 ]]], dtype=float32) - b(chain, draw)float32-0.6368493 -0.635342 ... -0.6911656
array([[-0.6368493 , -0.635342 , -0.68866193, ..., -0.5476906 , -0.59620386, -0.6911656 ]], dtype=float32) - __log_sigma_a(chain, draw)float32-1.1040249 ... -1.1985127
array([[-1.1040249, -1.0546951, -1.2069846, ..., -1.1648154, -1.0723704, -1.1985127]], dtype=float32) - __log_sigma(chain, draw)float32-0.32528934 ... -0.30933022
array([[-0.32528934, -0.2625135 , -0.34570464, ..., -0.3002294 , -0.27668455, -0.30933022]], dtype=float32) - sigma_a(chain, draw)float320.331534 0.3482986 ... 0.30164254
array([[0.331534 , 0.3482986 , 0.2990978 , ..., 0.31198025, 0.3421964 , 0.30164254]], dtype=float32) - sigma(chain, draw)float320.7223183 0.769116 ... 0.73393834
array([[0.7223183 , 0.769116 , 0.7077215 , ..., 0.74064827, 0.7582936 , 0.73393834]], dtype=float32)
- created_at :
- 2020-09-06T15:14:00.002746
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (a_county_dim_0: 85, chain: 1, draw: 2000) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 6 ... 1994 1995 1996 1997 1998 1999 * a_county_dim_0 (a_county_dim_0) int64 0 1 2 3 4 5 6 ... 79 80 81 82 83 84 Data variables: mu_a (chain, draw) float32 1.4493645 1.5067779 ... 1.5112383 a_county (chain, draw, a_county_dim_0) float32 1.782057 ... 1.7976772 b (chain, draw) float32 -0.6368493 -0.635342 ... -0.6911656 __log_sigma_a (chain, draw) float32 -1.1040249 -1.0546951 ... -1.1985127 __log_sigma (chain, draw) float32 -0.32528934 -0.2625135 ... -0.30933022 sigma_a (chain, draw) float32 0.331534 0.3482986 ... 0.30164254 sigma (chain, draw) float32 0.7223183 0.769116 ... 0.73393834 Attributes: created_at: 2020-09-06T15:14:00.002746 arviz_version: 0.9.0xarray.Dataset -
- obs_id: 919
- obs_id(obs_id)int640 1 2 3 4 5 ... 914 915 916 917 918
array([ 0, 1, 2, ..., 916, 917, 918])
- y(obs_id)float640.8329 0.8329 1.099 ... 1.335 1.099
array([ 0.83290912, 0.83290912, 1.09861229, 0.09531018, 1.16315081, 0.95551145, 0.47000363, 0.09531018, -0.22314355, 0.26236426, 0.26236426, 0.33647224, 0.40546511, -0.69314718, 0.18232156, 1.5260563 , 0.33647224, 0.78845736, 1.79175947, 1.22377543, 0.64185389, 1.70474809, 1.85629799, 0.69314718, 1.90210753, 1.16315081, 1.93152141, 1.96009478, 2.05412373, 1.66770682, 1.5260563 , 1.5040774 , 1.06471074, 2.10413415, 0.53062825, 1.45861502, 1.70474809, 1.41098697, 0.87546874, 1.09861229, 0.40546511, 1.22377543, 1.09861229, 0.64185389, -1.2039728 , 0.91629073, 0.18232156, 0.83290912, -0.35667494, 0.58778666, 1.09861229, 0.83290912, 0.58778666, 0.40546511, 0.69314718, 0.64185389, 0.26236426, 1.48160454, 1.5260563 , 1.85629799, 1.54756251, 1.75785792, 0.83290912, -0.69314718, 1.54756251, 1.5040774 , 1.90210753, 1.02961942, 1.09861229, 1.09861229, 1.98787435, 1.62924054, 0.99325177, 1.62924054, 2.57261223, 1.98787435, 1.93152141, 2.55722731, 1.77495235, 2.2617631 , 1.80828877, 1.36097655, 2.66722821, 0.64185389, 1.94591015, 1.56861592, 2.2617631 , 0.95551145, 1.91692261, 1.41098697, 2.32238772, 0.83290912, 0.64185389, 1.25276297, 1.74046617, 1.48160454, 1.38629436, 0.33647224, 1.45861502, -0.10536052, ... 1.80828877, 1.09861229, 1.91692261, 2.96527307, 1.41098697, 1.79175947, 2.20827441, 2.14006616, 0.18232156, 1.16315081, 2.4510051 , 2.27212589, 1.09861229, -0.22314355, 1.19392247, 1.56861592, 1.58923521, -0.69314718, 2.24070969, 0.58778666, 0. , 2.3321439 , 2.05412373, 0.83290912, 1.88706965, 2.50959926, 1.54756251, 1.84054963, 1.88706965, 1.06471074, 0.69314718, 0.26236426, 0.91629073, 0.09531018, 0.26236426, 0.53062825, -0.10536052, 0.58778666, 1.56861592, 0.58778666, 1.22377543, -0.10536052, 2.29253476, 1.68639895, 2.1517622 , 0.69314718, 1.90210753, 1.36097655, 1.79175947, 1.60943791, 0.95551145, 2.37954613, 0.91629073, 0.78845736, 1.56861592, 1.33500107, 2.60268969, 1.09861229, 1.48160454, 1.36097655, 0.64185389, 0.47000363, 0.64185389, 0.33647224, 1.90210753, 3.02042489, 1.80828877, 2.63188884, 2.3321439 , 1.75785792, 2.24070969, 1.25276297, 1.43508453, 2.45958884, 1.98787435, 1.56861592, 0.64185389, -0.22314355, 1.56861592, 2.3321439 , 2.43361336, 2.04122033, 2.4765384 , -0.51082562, 1.91692261, 1.68639895, 1.16315081, 0.78845736, 2.00148 , 1.64865863, 0.83290912, 0.87546874, 2.77258872, 2.2617631 , 1.87180218, 1.5260563 , 1.62924054, 1.33500107, 1.09861229])
- created_at :
- 2020-09-06T15:14:00.010940
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (obs_id: 919) Coordinates: * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 ... 911 912 913 914 915 916 917 918 Data variables: y (obs_id) float64 0.8329 0.8329 1.099 0.09531 ... 1.629 1.335 1.099 Attributes: created_at: 2020-09-06T15:14:00.010940 arviz_version: 0.9.0xarray.Dataset
varying_intercept_samples.assign_coords(**{"a_county_dim_0": mn_counties}, inplace=True)
az.plot_forest(varying_intercept_samples, var_names=["mu_a", "a_county"], combined=True, textsize=9
);

_, ax = plt.subplots(2, 2, figsize=(12, 8))
az.plot_posterior(varying_intercept_samples, var_names=["mu_a", "sigma_a", "b", "sigma"], ax=ax);

As we suspected, the estimate for the floor coefficient is reliably negative and centered around -0.67. This can be interpreted as houses without basements having about half ($\exp(-0.66) = 0.52$) the radon levels of those with basements, after accounting for county. With this, the estimated average regression line for all the counties can be written as $y = 1.5−0.67x$.
post = varying_intercept_samples.posterior # alias for readability
theta = (post.a_county + post.b * xvals).mean(dim=("chain", "draw")).to_dataset(name="Mean log radon")
_, ax = plt.subplots()
theta.plot.scatter(x="Level", y="Mean log radon", alpha=0.2, color="k", ax=ax) # scatter
ax.plot(xvals, theta["Mean log radon"].T,"k-", alpha=0.2); # add lines too
ax.set_title("Log Radon Estimates(Varying Intercepts)");

The graph above shows, for each county, the expected log radon level and the average effect of having no basement.
Let's compare partial pooling estimates with pooled and unpooled models.
varying_intercept_samples.observed_data = varying_intercept_samples.observed_data.assign_coords({
"County": ("obs_id", mn_counties[county_idx]),
"Level": ("obs_id", np.array(["Basement", "Floor"])[floor.values.astype(np.int32)])
})
fig, axes = plt.subplots(2, 4, figsize=(12, 6), sharey=True, sharex=True)
for ax, c in zip(axes.ravel(), SAMPLE_COUNTIES):
sample_county_mask = varying_intercept_samples.observed_data.County.isin([c])
# plot obs:
unpooled_advi_samples.observed_data.where(
sample_county_mask, drop=True
).sortby("Level").plot.scatter(x="Level", y="y", ax=ax, alpha=.4)
# plot both models:
ax.plot([0, 1], pooled_means.a, "r--", label="Complete pooling")
ax.plot([0, 1], unpooled_means.a_county.sel(a_county_dim_0=c) + unpooled_means.beta*xvals, "k:", label="No pooling")
ax.plot([0, 1], theta["Mean log radon"].sel(a_county_dim_0=c), "b", label="Partial pooling")
ax.set_title(c); ax.set_xlabel(""); ax.set_ylabel("")
axes[0,0].set_ylabel("Log radon level"); axes[1, 0].set_ylabel("Log radon level")
axes[0,0].legend(fontsize=8, frameon=True), axes[1, 0].legend(fontsize=8, frameon=True)
fig.tight_layout();
<ipython-input-37-0baef2f019b1>:25: UserWarning: This figure was using constrained_layout==True, but that is incompatible with subplots_adjust and or tight_layout: setting constrained_layout==False. fig.tight_layout();

Here we clearly see the notion that partial-pooling is a compromise between no pooling and complete pooling, as its mean estimates are usually between the other models’ estimates. And interestingly, the bigger (smaller) the sample size in a given county, the closer the partial-pooling estimates are to the no-pooling (complete-pooling) estimates.
Varying intercept and slope model¶
Let's model the effect floor by considering the slope to vary by county as well $$ y_i = \alpha_{j[i]} + \beta_{j[i]} + \epsilon_i $$
@pm.model
def varying_intercept_slope():
# Hyperpriors
mu_a = yield pm.Normal('mu_a', loc=0., scale=1.)
sigma_a = yield pm.HalfCauchy('sigma_a', scale=1.)
mu_b = yield pm.Normal('mu_b', loc=0., scale=1.)
sigma_b = yield pm.HalfCauchy('sigma_b', scale=1.)
# Intercept for each county, distributed around group mean mu_a
a_county = yield pm.Normal('a_county', loc=mu_a, scale=sigma_a, batch_stack=counties)
# Slope for each county, distributed around group mean mu_b
b_county = yield pm.Normal('b_county', loc=mu_b, scale=sigma_b, batch_stack=counties)
loc = tf.gather(a_county, county_idx) + tf.gather(b_county, county_idx) * data.floor.values
scale = yield pm.Exponential("sigma", rate=1.)
y = yield pm.Normal('y', loc=loc, scale=scale, observed=data.log_radon.values)
varying_intercept_slope_advi = pm.fit(varying_intercept_slope(), num_steps=25_000)
varying_intercept_slope_samples = varying_intercept_slope_advi.approximation.sample(2_000)
remove_scope(varying_intercept_slope_samples)
varying_intercept_slope_samples
|>>>>>>>>>>>>>>>>>>>>|
-
- a_county_dim_0: 85
- b_county_dim_0: 85
- chain: 1
- draw: 2000
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- a_county_dim_0(a_county_dim_0)int640 1 2 3 4 5 6 ... 79 80 81 82 83 84
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84]) - b_county_dim_0(b_county_dim_0)int640 1 2 3 4 5 6 ... 79 80 81 82 83 84
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84])
- mu_a(chain, draw)float321.4930406 1.4486337 ... 1.5145546
array([[1.4930406, 1.4486337, 1.4955258, ..., 1.4699484, 1.5402639, 1.5145546]], dtype=float32) - mu_b(chain, draw)float32-0.7048421 ... -0.59183025
array([[-0.7048421 , -0.64330596, -0.6644298 , ..., -0.6669646 , -0.60908604, -0.59183025]], dtype=float32) - a_county(chain, draw, a_county_dim_0)float321.1657196 1.054467 ... 0.59795755
array([[[1.1657196 , 1.054467 , 0.92647433, ..., 1.766197 , 1.6828083 , 1.6666431 ], [1.0680116 , 1.0140331 , 1.1937376 , ..., 1.3710928 , 1.591624 , 1.6319671 ], [1.1849082 , 0.97396046, 1.5205295 , ..., 1.8124071 , 1.4027165 , 1.4950168 ], ..., [1.2612067 , 0.96331567, 1.1616149 , ..., 1.4058344 , 1.1527064 , 1.3057501 ], [1.183216 , 0.9911122 , 1.6703023 , ..., 1.5332017 , 1.658561 , 1.4238042 ], [1.2632247 , 0.99801606, 1.8306286 , ..., 1.7863529 , 1.778602 , 0.59795755]]], dtype=float32) - b_county(chain, draw, b_county_dim_0)float32-0.370982 -0.7640928 ... -1.035405
array([[[-0.370982 , -0.7640928 , -0.93647075, ..., -1.3101674 , -0.8603058 , -0.76141113], [-0.46477285, -1.0195789 , -0.6515858 , ..., -1.3889568 , -0.8997741 , -0.4294933 ], [-0.4628898 , -1.5606394 , -0.4034984 , ..., -1.5112813 , -0.7789763 , -1.510519 ], ..., [-0.3307628 , -0.8429571 , -1.101429 , ..., -1.71626 , -0.5948556 , 0.08953285], [-0.30029684, -1.3296744 , -0.5047833 , ..., -1.3792053 , -0.00357264, -0.30857176], [-0.7416409 , -0.6979863 , -0.67211825, ..., -1.7206702 , -0.67385936, -1.035405 ]]], dtype=float32) - __log_sigma_a(chain, draw)float32-1.1933181 ... -1.1121558
array([[-1.1933181, -1.1757988, -1.1129156, ..., -1.0994793, -0.9975351, -1.1121558]], dtype=float32) - __log_sigma_b(chain, draw)float32-0.8809401 ... -0.6744319
array([[-0.8809401 , -0.96785593, -0.8011294 , ..., -1.0679553 , -0.85843027, -0.6744319 ]], dtype=float32) - __log_sigma(chain, draw)float32-0.35025468 ... -0.29480654
array([[-0.35025468, -0.34717098, -0.3214259 , ..., -0.344014 , -0.30487636, -0.29480654]], dtype=float32) - sigma_a(chain, draw)float320.30321348 0.3085724 ... 0.32884926
array([[0.30321348, 0.3085724 , 0.32859948, ..., 0.33304447, 0.36878735, 0.32884926]], dtype=float32) - sigma_b(chain, draw)float320.41439316 0.3798967 ... 0.5094457
array([[0.41439316, 0.3798967 , 0.44882178, ..., 0.3437106 , 0.42382687, 0.5094457 ]], dtype=float32) - sigma(chain, draw)float320.70450866 ... 0.74467564
array([[0.70450866, 0.70668447, 0.72511435, ..., 0.70891905, 0.7372145 , 0.74467564]], dtype=float32)
- created_at :
- 2020-09-06T15:14:36.909984
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (a_county_dim_0: 85, b_county_dim_0: 85, chain: 1, draw: 2000) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 6 ... 1994 1995 1996 1997 1998 1999 * a_county_dim_0 (a_county_dim_0) int64 0 1 2 3 4 5 6 ... 79 80 81 82 83 84 * b_county_dim_0 (b_county_dim_0) int64 0 1 2 3 4 5 6 ... 79 80 81 82 83 84 Data variables: mu_a (chain, draw) float32 1.4930406 1.4486337 ... 1.5145546 mu_b (chain, draw) float32 -0.7048421 -0.64330596 ... -0.59183025 a_county (chain, draw, a_county_dim_0) float32 1.1657196 ... 0.597... b_county (chain, draw, b_county_dim_0) float32 -0.370982 ... -1.03... __log_sigma_a (chain, draw) float32 -1.1933181 -1.1757988 ... -1.1121558 __log_sigma_b (chain, draw) float32 -0.8809401 -0.96785593 ... -0.6744319 __log_sigma (chain, draw) float32 -0.35025468 ... -0.29480654 sigma_a (chain, draw) float32 0.30321348 0.3085724 ... 0.32884926 sigma_b (chain, draw) float32 0.41439316 0.3798967 ... 0.5094457 sigma (chain, draw) float32 0.70450866 0.70668447 ... 0.74467564 Attributes: created_at: 2020-09-06T15:14:36.909984 arviz_version: 0.9.0xarray.Dataset -
- obs_id: 919
- obs_id(obs_id)int640 1 2 3 4 5 ... 914 915 916 917 918
array([ 0, 1, 2, ..., 916, 917, 918])
- y(obs_id)float640.8329 0.8329 1.099 ... 1.335 1.099
array([ 0.83290912, 0.83290912, 1.09861229, 0.09531018, 1.16315081, 0.95551145, 0.47000363, 0.09531018, -0.22314355, 0.26236426, 0.26236426, 0.33647224, 0.40546511, -0.69314718, 0.18232156, 1.5260563 , 0.33647224, 0.78845736, 1.79175947, 1.22377543, 0.64185389, 1.70474809, 1.85629799, 0.69314718, 1.90210753, 1.16315081, 1.93152141, 1.96009478, 2.05412373, 1.66770682, 1.5260563 , 1.5040774 , 1.06471074, 2.10413415, 0.53062825, 1.45861502, 1.70474809, 1.41098697, 0.87546874, 1.09861229, 0.40546511, 1.22377543, 1.09861229, 0.64185389, -1.2039728 , 0.91629073, 0.18232156, 0.83290912, -0.35667494, 0.58778666, 1.09861229, 0.83290912, 0.58778666, 0.40546511, 0.69314718, 0.64185389, 0.26236426, 1.48160454, 1.5260563 , 1.85629799, 1.54756251, 1.75785792, 0.83290912, -0.69314718, 1.54756251, 1.5040774 , 1.90210753, 1.02961942, 1.09861229, 1.09861229, 1.98787435, 1.62924054, 0.99325177, 1.62924054, 2.57261223, 1.98787435, 1.93152141, 2.55722731, 1.77495235, 2.2617631 , 1.80828877, 1.36097655, 2.66722821, 0.64185389, 1.94591015, 1.56861592, 2.2617631 , 0.95551145, 1.91692261, 1.41098697, 2.32238772, 0.83290912, 0.64185389, 1.25276297, 1.74046617, 1.48160454, 1.38629436, 0.33647224, 1.45861502, -0.10536052, ... 1.80828877, 1.09861229, 1.91692261, 2.96527307, 1.41098697, 1.79175947, 2.20827441, 2.14006616, 0.18232156, 1.16315081, 2.4510051 , 2.27212589, 1.09861229, -0.22314355, 1.19392247, 1.56861592, 1.58923521, -0.69314718, 2.24070969, 0.58778666, 0. , 2.3321439 , 2.05412373, 0.83290912, 1.88706965, 2.50959926, 1.54756251, 1.84054963, 1.88706965, 1.06471074, 0.69314718, 0.26236426, 0.91629073, 0.09531018, 0.26236426, 0.53062825, -0.10536052, 0.58778666, 1.56861592, 0.58778666, 1.22377543, -0.10536052, 2.29253476, 1.68639895, 2.1517622 , 0.69314718, 1.90210753, 1.36097655, 1.79175947, 1.60943791, 0.95551145, 2.37954613, 0.91629073, 0.78845736, 1.56861592, 1.33500107, 2.60268969, 1.09861229, 1.48160454, 1.36097655, 0.64185389, 0.47000363, 0.64185389, 0.33647224, 1.90210753, 3.02042489, 1.80828877, 2.63188884, 2.3321439 , 1.75785792, 2.24070969, 1.25276297, 1.43508453, 2.45958884, 1.98787435, 1.56861592, 0.64185389, -0.22314355, 1.56861592, 2.3321439 , 2.43361336, 2.04122033, 2.4765384 , -0.51082562, 1.91692261, 1.68639895, 1.16315081, 0.78845736, 2.00148 , 1.64865863, 0.83290912, 0.87546874, 2.77258872, 2.2617631 , 1.87180218, 1.5260563 , 1.62924054, 1.33500107, 1.09861229])
- created_at :
- 2020-09-06T15:14:36.914459
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (obs_id: 919) Coordinates: * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 ... 911 912 913 914 915 916 917 918 Data variables: y (obs_id) float64 0.8329 0.8329 1.099 0.09531 ... 1.629 1.335 1.099 Attributes: created_at: 2020-09-06T15:14:36.914459 arviz_version: 0.9.0xarray.Dataset
az.plot_trace(varying_intercept_slope_samples, compact=True)
<AxesSubplot:title={'center':'sigma'}>

post = varying_intercept_slope_samples.posterior # alias for readability
avg_a_county = post.a_county.mean(dim=("chain", "draw"))
avg_b_county = post.b_county.mean(dim=("chain", "draw"))
theta = (avg_a_county.rename(a_county_dim_0="County") + avg_b_county.rename(b_county_dim_0="County")*xvals).to_dataset(name="Mean log radon")
_, ax = plt.subplots()
theta.plot.scatter(x="Level", y="Mean log radon", alpha=0.2, color="k", ax=ax) #scatter
ax.plot(xvals, theta["Mean log radon"].T,"k-", alpha=0.2); # add lines too
ax.set_title("MEAN LOG RADON BY COUNTY");

We can see that now both the intercept and the slope vary by county. Now, the plan of action is to model the covariation between intercepts and slopes using MvNormal distribution.
Covariation intercept model¶
$$y \sim Normal(\theta, \sigma)$$
$$\theta = \alpha_{COUNTY} + \beta_{COUNTY} \times floor$$
$$\begin{bmatrix} \alpha_{COUNTY} \\ \beta_{COUNTY} \end{bmatrix} \sim MvNormal(\begin{bmatrix} \alpha \\ \beta \end{bmatrix}, \Sigma)$$
$$\Sigma = \begin{pmatrix} \sigma_{\alpha} & 0 \\ 0 & \sigma_{\beta} \end{pmatrix} P \begin{pmatrix} \sigma_{\alpha} & 0 \\ 0 & \sigma_{\beta} \end{pmatrix}$$
Every correlation matrix can be split into product of its Lower Traingular cholesky factors.
$$
P = L*L^T
$$
We will make use of LKJCholesky distribution from PyMC4 to generate lower triangular cholesky matrix $L$ and then to match its support from unconstrained space, we need to pass a bijector tfb.CorrelationCholesky as well. Variational Inference and even MCMC approximations work in unconstrained regions.
Read more here in PyMC3 docs about the use of LKJ priors and this blog post by Adam Haber to know more about correlation matrices.
class CorrelationCholesky(pm.distributions.transforms.BackwardTransform):
name = "cholesky"
def __init__(self):
transform = tfb.CorrelationCholesky()
super().__init__(transform)
@pm.model
def covariation_intercept_slope():
sigma_slope = yield pm.Exponential("sigma_slope", rate=tf.cast(1., tf.float64), batch_stack=2)
cov = yield pm.LKJCholesky('cov', dimension=2, concentration=tf.cast(2, tf.float64), transform=CorrelationCholesky())
# Hyperpriors
mu_a = yield pm.Normal('mu_a', loc=tf.cast(0., tf.float64), scale=tf.cast(5., tf.float64))
mu_b = yield pm.Normal('mu_b', loc=tf.cast(0., tf.float64), scale=tf.cast(5., tf.float64))
ab_county = yield pm.MvNormalCholesky(
'ab_county', tf.stack([mu_a, mu_b]), tf.linalg.LinearOperatorDiag(sigma_slope).matmul(cov), batch_stack=counties
)
loc = tf.gather(ab_county[:, 0], county_idx) + tf.gather(ab_county[:, 1], county_idx)*floor
scale = yield pm.Exponential("sigma", rate=tf.cast(1., tf.float64))
y = yield pm.Normal('y', loc=loc, scale=scale, observed=data.log_radon.values)
Let's also use higher sample_size to achieve better convergence.
covariation_intercept_slope_advi = pm.fit(covariation_intercept_slope(), num_steps=25_000, sample_size=10)
|>>>>>>>>>>>>>>>>>>>>|
plot_elbo(covariation_intercept_slope_advi.losses)

Since, the variable cov is a lower triangular matrix, we need to multiply it with its transpose to get back the correlation matrix.
covariation_intercept_slope_samples = covariation_intercept_slope_advi.approximation.sample(3_000)
remove_scope(covariation_intercept_slope_samples)
covariation_intercept_slope_samples.posterior["cov"].values = np.matmul(
covariation_intercept_slope_samples.posterior["cov"].values,
np.transpose(covariation_intercept_slope_samples.posterior["cov"].values, (0, 1, 3, 2))
)
covariation_intercept_slope_samples
-
- __cholesky_cov_dim_0: 1
- __log_sigma_slope_dim_0: 2
- ab_county_dim_0: 85
- ab_county_dim_1: 2
- chain: 1
- cov_dim_0: 2
- cov_dim_1: 2
- draw: 3000
- sigma_slope_dim_0: 2
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 ... 2996 2997 2998 2999
array([ 0, 1, 2, ..., 2997, 2998, 2999])
- ab_county_dim_0(ab_county_dim_0)int640 1 2 3 4 5 6 ... 79 80 81 82 83 84
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84]) - ab_county_dim_1(ab_county_dim_1)int640 1
array([0, 1])
- __log_sigma_slope_dim_0(__log_sigma_slope_dim_0)int640 1
array([0, 1])
- __cholesky_cov_dim_0(__cholesky_cov_dim_0)int640
array([0])
- sigma_slope_dim_0(sigma_slope_dim_0)int640 1
array([0, 1])
- cov_dim_0(cov_dim_0)int640 1
array([0, 1])
- cov_dim_1(cov_dim_1)int640 1
array([0, 1])
- mu_a(chain, draw)float641.503 1.477 1.507 ... 1.514 1.475
array([[1.50297226, 1.47662966, 1.50682203, ..., 1.4779058 , 1.51425872, 1.47520876]]) - mu_b(chain, draw)float64-0.6059 -0.6531 ... -0.6745 -0.6212
array([[-0.60593625, -0.65312248, -0.65703405, ..., -0.68033895, -0.67447093, -0.62119897]]) - ab_county(chain, draw, ab_county_dim_0, ab_county_dim_1)float640.9875 -0.8597 ... 0.9846 -0.7332
array([[[[ 0.98753613, -0.85973684], [ 1.05021129, -0.7599651 ], [ 1.56348613, -0.36307538], ..., [ 1.47539419, -0.93410477], [ 1.65063888, -0.89027457], [ 1.29922529, -0.80955917]], [[ 1.16472251, -1.00372091], [ 0.84512632, -0.59523111], [ 1.72337099, -0.73815348], ..., [ 1.53062087, -0.79304397], [ 1.61317101, -1.00879707], [ 1.5719441 , -1.12102989]], [[ 1.05842259, -0.62397016], [ 1.02017518, -0.55132196], [ 1.20530825, -0.3074609 ], ..., ... ..., [ 1.83136056, -1.23226503], [ 1.66181191, -0.79601287], [ 1.61483588, -0.23794943]], [[ 0.9120984 , -0.33232955], [ 1.06463707, -0.88007317], [ 1.2713347 , -0.69039174], ..., [ 1.81054568, -0.91925895], [ 1.67351613, -0.15251035], [ 0.74764682, -0.82722249]], [[ 1.46147561, -0.47514546], [ 1.15462958, -0.8816729 ], [ 1.83451009, -0.64952792], ..., [ 1.67841525, -1.21466439], [ 1.37997389, -0.83329095], [ 0.98462632, -0.73319583]]]]) - __log_sigma_slope(chain, draw, __log_sigma_slope_dim_0)float64-1.147 -1.101 ... -1.223 -1.285
array([[[-1.14733712, -1.1008361 ], [-1.11687183, -1.21949091], [-1.03124146, -1.31066995], ..., [-1.12076748, -1.25842616], [-1.03309974, -1.10501786], [-1.2232819 , -1.28534661]]]) - __cholesky_cov(chain, draw, __cholesky_cov_dim_0)float640.129 0.1551 ... -0.0003877 0.1431
array([[[ 0.12902331], [ 0.15508206], [ 0.15371682], ..., [ 0.07718439], [-0.00038772], [ 0.14305497]]]) - __log_sigma(chain, draw)float64-0.3541 -0.2946 ... -0.3602 -0.36
array([[-0.35409417, -0.29457169, -0.32894763, ..., -0.36121729, -0.36023511, -0.36002339]]) - sigma_slope(chain, draw, sigma_slope_dim_0)float640.3175 0.3326 ... 0.2943 0.2766
array([[[0.31748106, 0.33259289], [0.32730205, 0.2953805 ], [0.35656403, 0.26963935], ..., [0.32602948, 0.2841008 ], [0.35590205, 0.33120497], [0.29426284, 0.27655471]]]) - cov(chain, draw, cov_dim_0, cov_dim_1)float641.0 0.128 0.128 ... 0.1416 1.0
array([[[[ 1.00000000e+00, 1.27962607e-01], [ 1.27962607e-01, 1.00000000e+00]], [[ 1.00000000e+00, 1.53250139e-01], [ 1.53250139e-01, 1.00000000e+00]], [[ 1.00000000e+00, 1.51932302e-01], [ 1.51932302e-01, 1.00000000e+00]], ..., [[ 1.00000000e+00, 7.69555066e-02], [ 7.69555066e-02, 1.00000000e+00]], [[ 1.00000000e+00, -3.87716149e-04], [-3.87716149e-04, 1.00000000e+00]], [[ 1.00000000e+00, 1.41613274e-01], [ 1.41613274e-01, 1.00000000e+00]]]]) - sigma(chain, draw)float640.7018 0.7449 ... 0.6975 0.6977
array([[0.70180887, 0.74485055, 0.71968071, ..., 0.69682757, 0.69751231, 0.69766001]])
- created_at :
- 2020-09-06T15:16:05.404673
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (__cholesky_cov_dim_0: 1, __log_sigma_slope_dim_0: 2, ab_county_dim_0: 85, ab_county_dim_1: 2, chain: 1, cov_dim_0: 2, cov_dim_1: 2, draw: 3000, sigma_slope_dim_0: 2) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 ... 2995 2996 2997 2998 2999 * ab_county_dim_0 (ab_county_dim_0) int64 0 1 2 3 4 ... 81 82 83 84 * ab_county_dim_1 (ab_county_dim_1) int64 0 1 * __log_sigma_slope_dim_0 (__log_sigma_slope_dim_0) int64 0 1 * __cholesky_cov_dim_0 (__cholesky_cov_dim_0) int64 0 * sigma_slope_dim_0 (sigma_slope_dim_0) int64 0 1 * cov_dim_0 (cov_dim_0) int64 0 1 * cov_dim_1 (cov_dim_1) int64 0 1 Data variables: mu_a (chain, draw) float64 1.503 1.477 ... 1.514 1.475 mu_b (chain, draw) float64 -0.6059 -0.6531 ... -0.6212 ab_county (chain, draw, ab_county_dim_0, ab_county_dim_1) float64 ... __log_sigma_slope (chain, draw, __log_sigma_slope_dim_0) float64 -... __cholesky_cov (chain, draw, __cholesky_cov_dim_0) float64 0.12... __log_sigma (chain, draw) float64 -0.3541 -0.2946 ... -0.36 sigma_slope (chain, draw, sigma_slope_dim_0) float64 0.3175 ... cov (chain, draw, cov_dim_0, cov_dim_1) float64 1.0 ... sigma (chain, draw) float64 0.7018 0.7449 ... 0.6977 Attributes: created_at: 2020-09-06T15:16:05.404673 arviz_version: 0.9.0xarray.Dataset -
- obs_id: 919
- obs_id(obs_id)int640 1 2 3 4 5 ... 914 915 916 917 918
array([ 0, 1, 2, ..., 916, 917, 918])
- y(obs_id)float640.8329 0.8329 1.099 ... 1.335 1.099
array([ 0.83290912, 0.83290912, 1.09861229, 0.09531018, 1.16315081, 0.95551145, 0.47000363, 0.09531018, -0.22314355, 0.26236426, 0.26236426, 0.33647224, 0.40546511, -0.69314718, 0.18232156, 1.5260563 , 0.33647224, 0.78845736, 1.79175947, 1.22377543, 0.64185389, 1.70474809, 1.85629799, 0.69314718, 1.90210753, 1.16315081, 1.93152141, 1.96009478, 2.05412373, 1.66770682, 1.5260563 , 1.5040774 , 1.06471074, 2.10413415, 0.53062825, 1.45861502, 1.70474809, 1.41098697, 0.87546874, 1.09861229, 0.40546511, 1.22377543, 1.09861229, 0.64185389, -1.2039728 , 0.91629073, 0.18232156, 0.83290912, -0.35667494, 0.58778666, 1.09861229, 0.83290912, 0.58778666, 0.40546511, 0.69314718, 0.64185389, 0.26236426, 1.48160454, 1.5260563 , 1.85629799, 1.54756251, 1.75785792, 0.83290912, -0.69314718, 1.54756251, 1.5040774 , 1.90210753, 1.02961942, 1.09861229, 1.09861229, 1.98787435, 1.62924054, 0.99325177, 1.62924054, 2.57261223, 1.98787435, 1.93152141, 2.55722731, 1.77495235, 2.2617631 , 1.80828877, 1.36097655, 2.66722821, 0.64185389, 1.94591015, 1.56861592, 2.2617631 , 0.95551145, 1.91692261, 1.41098697, 2.32238772, 0.83290912, 0.64185389, 1.25276297, 1.74046617, 1.48160454, 1.38629436, 0.33647224, 1.45861502, -0.10536052, ... 1.80828877, 1.09861229, 1.91692261, 2.96527307, 1.41098697, 1.79175947, 2.20827441, 2.14006616, 0.18232156, 1.16315081, 2.4510051 , 2.27212589, 1.09861229, -0.22314355, 1.19392247, 1.56861592, 1.58923521, -0.69314718, 2.24070969, 0.58778666, 0. , 2.3321439 , 2.05412373, 0.83290912, 1.88706965, 2.50959926, 1.54756251, 1.84054963, 1.88706965, 1.06471074, 0.69314718, 0.26236426, 0.91629073, 0.09531018, 0.26236426, 0.53062825, -0.10536052, 0.58778666, 1.56861592, 0.58778666, 1.22377543, -0.10536052, 2.29253476, 1.68639895, 2.1517622 , 0.69314718, 1.90210753, 1.36097655, 1.79175947, 1.60943791, 0.95551145, 2.37954613, 0.91629073, 0.78845736, 1.56861592, 1.33500107, 2.60268969, 1.09861229, 1.48160454, 1.36097655, 0.64185389, 0.47000363, 0.64185389, 0.33647224, 1.90210753, 3.02042489, 1.80828877, 2.63188884, 2.3321439 , 1.75785792, 2.24070969, 1.25276297, 1.43508453, 2.45958884, 1.98787435, 1.56861592, 0.64185389, -0.22314355, 1.56861592, 2.3321439 , 2.43361336, 2.04122033, 2.4765384 , -0.51082562, 1.91692261, 1.68639895, 1.16315081, 0.78845736, 2.00148 , 1.64865863, 0.83290912, 0.87546874, 2.77258872, 2.2617631 , 1.87180218, 1.5260563 , 1.62924054, 1.33500107, 1.09861229])
- created_at :
- 2020-09-06T15:16:05.413183
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (obs_id: 919) Coordinates: * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 ... 911 912 913 914 915 916 917 918 Data variables: y (obs_id) float64 0.8329 0.8329 1.099 0.09531 ... 1.629 1.335 1.099 Attributes: created_at: 2020-09-06T15:16:05.413183 arviz_version: 0.9.0xarray.Dataset
az.plot_forest(
[varying_intercept_slope_samples, covariation_intercept_slope_samples],
model_names=["No covariation", "With covariation"],
var_names=["mu_a", "mu_b", "cov"],
combined=True,
figsize=(7.5, 5),
);

covariation_intercept_slope_samples.posterior["cov"].mean(dim=["chain", "draw"]).values
array([[1. , 0.06146909],
[0.06146909, 1. ]])
Observing from the forest plot and the mean values, the correlation matrix is close to the Identity matrix. So, it is not a good idea to model the correlation using Mean Field ADVI as it fits the model with Diagonal Gaussian distribution. In general, any VI approximation does not care about hierarchies in the model. All it considers is to optimizer ELBO in an unbounded space.
We have FullRank ADVI as a rescue that poses dense covariance matrix over all the parameters but it requires more memory and computational resources. Let's figure out if FullRank ADVI can capture some correlations.
covariation_intercept_full_rank = pm.fit(covariation_intercept_slope(), sample_size=10,
num_steps=25_000, method="fullrank_advi")
plot_elbo(covariation_intercept_full_rank.losses)
|>>>>>>>>>>>>>>>>>>>>|

covariation_intercept_full_rank_samples = covariation_intercept_full_rank.approximation.sample(4_000)
remove_scope(covariation_intercept_full_rank_samples)
covariation_intercept_full_rank_samples.posterior["cov"].values = np.matmul(
covariation_intercept_full_rank_samples.posterior["cov"].values,
np.transpose(covariation_intercept_full_rank_samples.posterior["cov"].values, (0, 1, 3, 2))
)
covariation_intercept_full_rank_samples
-
- __cholesky_cov_dim_0: 1
- __log_sigma_slope_dim_0: 2
- ab_county_dim_0: 85
- ab_county_dim_1: 2
- chain: 1
- cov_dim_0: 2
- cov_dim_1: 2
- draw: 4000
- sigma_slope_dim_0: 2
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 ... 3996 3997 3998 3999
array([ 0, 1, 2, ..., 3997, 3998, 3999])
- ab_county_dim_0(ab_county_dim_0)int640 1 2 3 4 5 6 ... 79 80 81 82 83 84
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84]) - ab_county_dim_1(ab_county_dim_1)int640 1
array([0, 1])
- __log_sigma_slope_dim_0(__log_sigma_slope_dim_0)int640 1
array([0, 1])
- __cholesky_cov_dim_0(__cholesky_cov_dim_0)int640
array([0])
- sigma_slope_dim_0(sigma_slope_dim_0)int640 1
array([0, 1])
- cov_dim_0(cov_dim_0)int640 1
array([0, 1])
- cov_dim_1(cov_dim_1)int640 1
array([0, 1])
- mu_a(chain, draw)float641.442 1.411 1.458 ... 1.505 1.545
array([[1.44157145, 1.41055974, 1.45796375, ..., 1.52769818, 1.50495889, 1.54501587]]) - mu_b(chain, draw)float64-0.5519 -0.6372 ... -0.5429 -0.6588
array([[-0.55185719, -0.63719361, -0.64991064, ..., -0.60575006, -0.54286851, -0.65876789]]) - ab_county(chain, draw, ab_county_dim_0, ab_county_dim_1)float641.103 0.06178 ... 1.495 -0.6167
array([[[[ 1.10251159, 0.06177962], [ 1.01775006, -0.99013645], [ 1.84532091, -0.84903852], ..., [ 1.97449864, -1.73696854], [ 1.44512079, -0.43008124], [ 1.19366699, -0.38549995]], [[ 1.33938165, 0.00469697], [ 0.9895481 , -1.1903016 ], [ 1.2565043 , -0.77370252], ..., [ 1.87720212, -1.0297701 ], [ 1.51530009, -1.25217816], [ 1.63933693, -1.10597871]], [[ 1.41299128, -0.17744921], [ 1.06667489, -0.85125227], [ 1.17068493, -0.29846862], ..., ... ..., [ 1.38249088, -1.40076622], [ 1.33664203, -1.0479582 ], [ 1.43800977, -0.04056126]], [[ 1.40232621, -0.65257964], [ 0.92013147, -0.43971042], [ 1.83521221, -1.1151818 ], ..., [ 1.78657534, -1.38489233], [ 1.49688109, -0.39415821], [ 1.19360837, -0.62458023]], [[ 1.19015241, 0.07429586], [ 0.83547864, -0.04993358], [ 1.34631223, -0.56156258], ..., [ 1.40184397, -1.46157653], [ 1.37037403, -1.38986458], [ 1.49538317, -0.61670657]]]]) - __log_sigma_slope(chain, draw, __log_sigma_slope_dim_0)float64-1.085 -0.9142 ... -1.115 -0.7669
array([[[-1.08524326, -0.91422757], [-0.79367875, -0.79953138], [-1.04254996, -0.78783721], ..., [-1.18658476, -0.76931894], [-1.30549297, -0.92132119], [-1.11496116, -0.76692019]]]) - __cholesky_cov(chain, draw, __cholesky_cov_dim_0)float640.0476 -0.3562 ... -0.4336 -0.1848
array([[[ 0.04759938], [-0.35615479], [-0.19981954], ..., [ 0.03669606], [-0.43361397], [-0.18476808]]]) - __log_sigma(chain, draw)float64-0.3121 -0.2898 ... -0.303 -0.3897
array([[-0.312052 , -0.28976289, -0.2830244 , ..., -0.33111312, -0.30304402, -0.38970624]]) - sigma_slope(chain, draw, sigma_slope_dim_0)float640.3378 0.4008 ... 0.3279 0.4644
array([[[0.3378196 , 0.40082612], [0.45217828, 0.44953958], [0.35255454, 0.45482743], ..., [0.30526203, 0.46332851], [0.27103889, 0.39799287], [0.32792802, 0.46444126]]]) - cov(chain, draw, cov_dim_0, cov_dim_1)float641.0 0.04755 0.04755 ... -0.1817 1.0
array([[[[ 1. , 0.04754555], [ 0.04754555, 1. ]], [[ 1. , -0.33551077], [-0.33551077, 1. ]], [[ 1. , -0.19594598], [-0.19594598, 1. ]], ..., [[ 1. , 0.03667138], [ 0.03667138, 1. ]], [[ 1. , -0.3978242 ], [-0.3978242 , 1. ]], [[ 1. , -0.18169268], [-0.18169268, 1. ]]]]) - sigma(chain, draw)float640.7319 0.7484 ... 0.7386 0.6773
array([[0.73194347, 0.74844101, 0.7535014 , ..., 0.71812393, 0.73856659, 0.6772558 ]])
- created_at :
- 2020-09-06T15:18:55.592877
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (__cholesky_cov_dim_0: 1, __log_sigma_slope_dim_0: 2, ab_county_dim_0: 85, ab_county_dim_1: 2, chain: 1, cov_dim_0: 2, cov_dim_1: 2, draw: 4000, sigma_slope_dim_0: 2) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 ... 3995 3996 3997 3998 3999 * ab_county_dim_0 (ab_county_dim_0) int64 0 1 2 3 4 ... 81 82 83 84 * ab_county_dim_1 (ab_county_dim_1) int64 0 1 * __log_sigma_slope_dim_0 (__log_sigma_slope_dim_0) int64 0 1 * __cholesky_cov_dim_0 (__cholesky_cov_dim_0) int64 0 * sigma_slope_dim_0 (sigma_slope_dim_0) int64 0 1 * cov_dim_0 (cov_dim_0) int64 0 1 * cov_dim_1 (cov_dim_1) int64 0 1 Data variables: mu_a (chain, draw) float64 1.442 1.411 ... 1.505 1.545 mu_b (chain, draw) float64 -0.5519 -0.6372 ... -0.6588 ab_county (chain, draw, ab_county_dim_0, ab_county_dim_1) float64 ... __log_sigma_slope (chain, draw, __log_sigma_slope_dim_0) float64 -... __cholesky_cov (chain, draw, __cholesky_cov_dim_0) float64 0.04... __log_sigma (chain, draw) float64 -0.3121 -0.2898 ... -0.3897 sigma_slope (chain, draw, sigma_slope_dim_0) float64 0.3378 ... cov (chain, draw, cov_dim_0, cov_dim_1) float64 1.0 ... sigma (chain, draw) float64 0.7319 0.7484 ... 0.6773 Attributes: created_at: 2020-09-06T15:18:55.592877 arviz_version: 0.9.0xarray.Dataset -
- obs_id: 919
- obs_id(obs_id)int640 1 2 3 4 5 ... 914 915 916 917 918
array([ 0, 1, 2, ..., 916, 917, 918])
- y(obs_id)float640.8329 0.8329 1.099 ... 1.335 1.099
array([ 0.83290912, 0.83290912, 1.09861229, 0.09531018, 1.16315081, 0.95551145, 0.47000363, 0.09531018, -0.22314355, 0.26236426, 0.26236426, 0.33647224, 0.40546511, -0.69314718, 0.18232156, 1.5260563 , 0.33647224, 0.78845736, 1.79175947, 1.22377543, 0.64185389, 1.70474809, 1.85629799, 0.69314718, 1.90210753, 1.16315081, 1.93152141, 1.96009478, 2.05412373, 1.66770682, 1.5260563 , 1.5040774 , 1.06471074, 2.10413415, 0.53062825, 1.45861502, 1.70474809, 1.41098697, 0.87546874, 1.09861229, 0.40546511, 1.22377543, 1.09861229, 0.64185389, -1.2039728 , 0.91629073, 0.18232156, 0.83290912, -0.35667494, 0.58778666, 1.09861229, 0.83290912, 0.58778666, 0.40546511, 0.69314718, 0.64185389, 0.26236426, 1.48160454, 1.5260563 , 1.85629799, 1.54756251, 1.75785792, 0.83290912, -0.69314718, 1.54756251, 1.5040774 , 1.90210753, 1.02961942, 1.09861229, 1.09861229, 1.98787435, 1.62924054, 0.99325177, 1.62924054, 2.57261223, 1.98787435, 1.93152141, 2.55722731, 1.77495235, 2.2617631 , 1.80828877, 1.36097655, 2.66722821, 0.64185389, 1.94591015, 1.56861592, 2.2617631 , 0.95551145, 1.91692261, 1.41098697, 2.32238772, 0.83290912, 0.64185389, 1.25276297, 1.74046617, 1.48160454, 1.38629436, 0.33647224, 1.45861502, -0.10536052, ... 1.80828877, 1.09861229, 1.91692261, 2.96527307, 1.41098697, 1.79175947, 2.20827441, 2.14006616, 0.18232156, 1.16315081, 2.4510051 , 2.27212589, 1.09861229, -0.22314355, 1.19392247, 1.56861592, 1.58923521, -0.69314718, 2.24070969, 0.58778666, 0. , 2.3321439 , 2.05412373, 0.83290912, 1.88706965, 2.50959926, 1.54756251, 1.84054963, 1.88706965, 1.06471074, 0.69314718, 0.26236426, 0.91629073, 0.09531018, 0.26236426, 0.53062825, -0.10536052, 0.58778666, 1.56861592, 0.58778666, 1.22377543, -0.10536052, 2.29253476, 1.68639895, 2.1517622 , 0.69314718, 1.90210753, 1.36097655, 1.79175947, 1.60943791, 0.95551145, 2.37954613, 0.91629073, 0.78845736, 1.56861592, 1.33500107, 2.60268969, 1.09861229, 1.48160454, 1.36097655, 0.64185389, 0.47000363, 0.64185389, 0.33647224, 1.90210753, 3.02042489, 1.80828877, 2.63188884, 2.3321439 , 1.75785792, 2.24070969, 1.25276297, 1.43508453, 2.45958884, 1.98787435, 1.56861592, 0.64185389, -0.22314355, 1.56861592, 2.3321439 , 2.43361336, 2.04122033, 2.4765384 , -0.51082562, 1.91692261, 1.68639895, 1.16315081, 0.78845736, 2.00148 , 1.64865863, 0.83290912, 0.87546874, 2.77258872, 2.2617631 , 1.87180218, 1.5260563 , 1.62924054, 1.33500107, 1.09861229])
- created_at :
- 2020-09-06T15:18:55.601440
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (obs_id: 919) Coordinates: * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 ... 911 912 913 914 915 916 917 918 Data variables: y (obs_id) float64 0.8329 0.8329 1.099 0.09531 ... 1.629 1.335 1.099 Attributes: created_at: 2020-09-06T15:18:55.601440 arviz_version: 0.9.0xarray.Dataset
az.plot_forest(
[varying_intercept_slope_samples, covariation_intercept_slope_samples, covariation_intercept_full_rank_samples],
model_names=["No covariation", "With covariation Mean Field", "With covariation Full Rank"],
var_names=["mu_a", "mu_b", "cov"],
combined=True,
figsize=(8, 8),
);

So the correlation between slopes and intercepts seems to be negative: when a_county increases, b_county tends to decrease. Also the estimates are close for both mu and sigma when using fullrank_advi. MeanField and FullRank ADVI are extreme ends of computing correlations. But now, PyMC4 comes with a LowRank ADVI approximation to let us decide how much correlation we wish to see.
covariation_intercept_slope_advi.approximation.order.size
176
The flattened shape of all parameters in our model is 176. So, we can specify a rank anyway between 1 and 176. Closer to zero, represents MeanField behaviour and closer to 176, resembles FullRank behaviour.
covariation_intercept_low_rank = pm.fit(covariation_intercept_slope(), num_steps=20_000, method="lowrank_advi",
sample_size=10, approx_kwargs=dict(rank=50))
plot_elbo(covariation_intercept_low_rank.losses)
|>>>>>>>>>>>>>>>>>>>>|

covariation_intercept_low_rank_samples = covariation_intercept_low_rank.approximation.sample(4_000)
remove_scope(covariation_intercept_low_rank_samples)
covariation_intercept_low_rank_samples.posterior["cov"].values = np.matmul(
covariation_intercept_low_rank_samples.posterior["cov"].values,
np.transpose(covariation_intercept_low_rank_samples.posterior["cov"].values, (0, 1, 3, 2))
)
covariation_intercept_low_rank_samples
-
- __cholesky_cov_dim_0: 1
- __log_sigma_slope_dim_0: 2
- ab_county_dim_0: 85
- ab_county_dim_1: 2
- chain: 1
- cov_dim_0: 2
- cov_dim_1: 2
- draw: 4000
- sigma_slope_dim_0: 2
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 ... 3996 3997 3998 3999
array([ 0, 1, 2, ..., 3997, 3998, 3999])
- ab_county_dim_0(ab_county_dim_0)int640 1 2 3 4 5 6 ... 79 80 81 82 83 84
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84]) - ab_county_dim_1(ab_county_dim_1)int640 1
array([0, 1])
- __log_sigma_slope_dim_0(__log_sigma_slope_dim_0)int640 1
array([0, 1])
- __cholesky_cov_dim_0(__cholesky_cov_dim_0)int640
array([0])
- sigma_slope_dim_0(sigma_slope_dim_0)int640 1
array([0, 1])
- cov_dim_0(cov_dim_0)int640 1
array([0, 1])
- cov_dim_1(cov_dim_1)int640 1
array([0, 1])
- mu_a(chain, draw)float641.509 1.498 1.426 ... 1.532 1.449
array([[1.50925392, 1.49795824, 1.42629924, ..., 1.5308051 , 1.53216212, 1.44900649]]) - mu_b(chain, draw)float64-0.6815 -0.5409 ... -0.6193 -0.593
array([[-0.68151757, -0.54089748, -0.56782709, ..., -0.76452922, -0.61933998, -0.59300725]]) - ab_county(chain, draw, ab_county_dim_0, ab_county_dim_1)float641.177 -0.8777 ... 0.9354 -0.7091
array([[[[ 1.17699098, -0.87772655], [ 0.8719603 , -0.71295297], [ 1.82976076, -0.47848699], ..., [ 1.66878237, -0.63678348], [ 1.78509161, -0.97226677], [ 1.38019166, -0.94294452]], [[ 0.98922584, -0.14417853], [ 1.03280072, -0.9385154 ], [ 1.34471995, -0.60151779], ..., [ 1.41518306, -1.00600861], [ 1.92616453, -0.18611176], [ 1.43425089, -0.62545378]], [[ 1.43652147, -0.81952798], [ 0.93561256, -0.62141368], [ 1.7604567 , -0.65514191], ..., ... ..., [ 1.42641328, -0.92645284], [ 1.74696447, -0.85951273], [ 1.34936729, -1.16444385]], [[ 0.74230133, -0.34197424], [ 0.9600017 , -1.20626791], [ 1.78019199, -0.74515731], ..., [ 1.8721507 , -1.05775905], [ 1.74983331, -0.5792016 ], [ 1.3991723 , -0.36454429]], [[ 1.26957593, -0.35145346], [ 0.88842673, -0.62990523], [ 1.33597802, -0.49303204], ..., [ 1.70985002, -0.59150253], [ 1.78929784, -0.63468222], [ 0.93541207, -0.70910543]]]]) - __log_sigma_slope(chain, draw, __log_sigma_slope_dim_0)float64-1.031 -1.275 ... -1.413 -1.243
array([[[-1.03128578, -1.27532842], [-1.03294963, -1.07077614], [-1.27912088, -1.10397565], ..., [-1.24034039, -1.03842296], [-1.15618308, -0.9692149 ], [-1.41318963, -1.2434011 ]]]) - __cholesky_cov(chain, draw, __cholesky_cov_dim_0)float64-0.04151 -0.0801 ... 0.03822
array([[[-0.04150945], [-0.08010301], [-0.0301403 ], ..., [-0.06599168], [-0.09905543], [ 0.0382171 ]]]) - __log_sigma(chain, draw)float64-0.3119 -0.3696 ... -0.2936 -0.3382
array([[-0.31192621, -0.36962706, -0.33602381, ..., -0.31870618, -0.29359504, -0.33817581]]) - sigma_slope(chain, draw, sigma_slope_dim_0)float640.3565 0.2793 ... 0.2434 0.2884
array([[[0.35654822, 0.27933921], [0.35595547, 0.3427424 ], [0.27828184, 0.33155033], ..., [0.28928573, 0.35401253], [0.31468502, 0.37938077], [0.2433658 , 0.28840167]]]) - cov(chain, draw, cov_dim_0, cov_dim_1)float641.0 -0.04147 ... 0.03819 1.0
array([[[[ 1. , -0.04147374], [-0.04147374, 1. ]], [[ 1. , -0.07984725], [-0.07984725, 1. ]], [[ 1. , -0.03012662], [-0.03012662, 1. ]], ..., [[ 1. , -0.06584846], [-0.06584846, 1. ]], [[ 1. , -0.09857301], [-0.09857301, 1. ]], [[ 1. , 0.03818922], [ 0.03818922, 1. ]]]]) - sigma(chain, draw)float640.732 0.691 ... 0.7456 0.7131
array([[0.73203555, 0.69099198, 0.71460609, ..., 0.72708915, 0.74557836, 0.71306991]])
- created_at :
- 2020-09-06T15:20:40.418225
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (__cholesky_cov_dim_0: 1, __log_sigma_slope_dim_0: 2, ab_county_dim_0: 85, ab_county_dim_1: 2, chain: 1, cov_dim_0: 2, cov_dim_1: 2, draw: 4000, sigma_slope_dim_0: 2) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 ... 3995 3996 3997 3998 3999 * ab_county_dim_0 (ab_county_dim_0) int64 0 1 2 3 4 ... 81 82 83 84 * ab_county_dim_1 (ab_county_dim_1) int64 0 1 * __log_sigma_slope_dim_0 (__log_sigma_slope_dim_0) int64 0 1 * __cholesky_cov_dim_0 (__cholesky_cov_dim_0) int64 0 * sigma_slope_dim_0 (sigma_slope_dim_0) int64 0 1 * cov_dim_0 (cov_dim_0) int64 0 1 * cov_dim_1 (cov_dim_1) int64 0 1 Data variables: mu_a (chain, draw) float64 1.509 1.498 ... 1.532 1.449 mu_b (chain, draw) float64 -0.6815 -0.5409 ... -0.593 ab_county (chain, draw, ab_county_dim_0, ab_county_dim_1) float64 ... __log_sigma_slope (chain, draw, __log_sigma_slope_dim_0) float64 -... __cholesky_cov (chain, draw, __cholesky_cov_dim_0) float64 -0.0... __log_sigma (chain, draw) float64 -0.3119 -0.3696 ... -0.3382 sigma_slope (chain, draw, sigma_slope_dim_0) float64 0.3565 ... cov (chain, draw, cov_dim_0, cov_dim_1) float64 1.0 ... sigma (chain, draw) float64 0.732 0.691 ... 0.7456 0.7131 Attributes: created_at: 2020-09-06T15:20:40.418225 arviz_version: 0.9.0xarray.Dataset -
- obs_id: 919
- obs_id(obs_id)int640 1 2 3 4 5 ... 914 915 916 917 918
array([ 0, 1, 2, ..., 916, 917, 918])
- y(obs_id)float640.8329 0.8329 1.099 ... 1.335 1.099
array([ 0.83290912, 0.83290912, 1.09861229, 0.09531018, 1.16315081, 0.95551145, 0.47000363, 0.09531018, -0.22314355, 0.26236426, 0.26236426, 0.33647224, 0.40546511, -0.69314718, 0.18232156, 1.5260563 , 0.33647224, 0.78845736, 1.79175947, 1.22377543, 0.64185389, 1.70474809, 1.85629799, 0.69314718, 1.90210753, 1.16315081, 1.93152141, 1.96009478, 2.05412373, 1.66770682, 1.5260563 , 1.5040774 , 1.06471074, 2.10413415, 0.53062825, 1.45861502, 1.70474809, 1.41098697, 0.87546874, 1.09861229, 0.40546511, 1.22377543, 1.09861229, 0.64185389, -1.2039728 , 0.91629073, 0.18232156, 0.83290912, -0.35667494, 0.58778666, 1.09861229, 0.83290912, 0.58778666, 0.40546511, 0.69314718, 0.64185389, 0.26236426, 1.48160454, 1.5260563 , 1.85629799, 1.54756251, 1.75785792, 0.83290912, -0.69314718, 1.54756251, 1.5040774 , 1.90210753, 1.02961942, 1.09861229, 1.09861229, 1.98787435, 1.62924054, 0.99325177, 1.62924054, 2.57261223, 1.98787435, 1.93152141, 2.55722731, 1.77495235, 2.2617631 , 1.80828877, 1.36097655, 2.66722821, 0.64185389, 1.94591015, 1.56861592, 2.2617631 , 0.95551145, 1.91692261, 1.41098697, 2.32238772, 0.83290912, 0.64185389, 1.25276297, 1.74046617, 1.48160454, 1.38629436, 0.33647224, 1.45861502, -0.10536052, ... 1.80828877, 1.09861229, 1.91692261, 2.96527307, 1.41098697, 1.79175947, 2.20827441, 2.14006616, 0.18232156, 1.16315081, 2.4510051 , 2.27212589, 1.09861229, -0.22314355, 1.19392247, 1.56861592, 1.58923521, -0.69314718, 2.24070969, 0.58778666, 0. , 2.3321439 , 2.05412373, 0.83290912, 1.88706965, 2.50959926, 1.54756251, 1.84054963, 1.88706965, 1.06471074, 0.69314718, 0.26236426, 0.91629073, 0.09531018, 0.26236426, 0.53062825, -0.10536052, 0.58778666, 1.56861592, 0.58778666, 1.22377543, -0.10536052, 2.29253476, 1.68639895, 2.1517622 , 0.69314718, 1.90210753, 1.36097655, 1.79175947, 1.60943791, 0.95551145, 2.37954613, 0.91629073, 0.78845736, 1.56861592, 1.33500107, 2.60268969, 1.09861229, 1.48160454, 1.36097655, 0.64185389, 0.47000363, 0.64185389, 0.33647224, 1.90210753, 3.02042489, 1.80828877, 2.63188884, 2.3321439 , 1.75785792, 2.24070969, 1.25276297, 1.43508453, 2.45958884, 1.98787435, 1.56861592, 0.64185389, -0.22314355, 1.56861592, 2.3321439 , 2.43361336, 2.04122033, 2.4765384 , -0.51082562, 1.91692261, 1.68639895, 1.16315081, 0.78845736, 2.00148 , 1.64865863, 0.83290912, 0.87546874, 2.77258872, 2.2617631 , 1.87180218, 1.5260563 , 1.62924054, 1.33500107, 1.09861229])
- created_at :
- 2020-09-06T15:20:40.423839
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (obs_id: 919) Coordinates: * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 ... 911 912 913 914 915 916 917 918 Data variables: y (obs_id) float64 0.8329 0.8329 1.099 0.09531 ... 1.629 1.335 1.099 Attributes: created_at: 2020-09-06T15:20:40.423839 arviz_version: 0.9.0xarray.Dataset
covariation_intercept_low_rank_150 = pm.fit(covariation_intercept_slope(), num_steps=20_000, method="lowrank_advi",
sample_size=10, approx_kwargs=dict(rank=150))
|>>>>>>>>>>>>>>>>>>>>|
covariation_intercept_low_rank_150_samples = covariation_intercept_low_rank_150.approximation.sample(4_000)
remove_scope(covariation_intercept_low_rank_150_samples)
covariation_intercept_low_rank_150_samples.posterior["cov"].values = np.matmul(
covariation_intercept_low_rank_150_samples.posterior["cov"].values,
np.transpose(covariation_intercept_low_rank_150_samples.posterior["cov"].values, (0, 1, 3, 2))
)
covariation_intercept_low_rank_150_samples
-
- __cholesky_cov_dim_0: 1
- __log_sigma_slope_dim_0: 2
- ab_county_dim_0: 85
- ab_county_dim_1: 2
- chain: 1
- cov_dim_0: 2
- cov_dim_1: 2
- draw: 4000
- sigma_slope_dim_0: 2
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 ... 3996 3997 3998 3999
array([ 0, 1, 2, ..., 3997, 3998, 3999])
- ab_county_dim_0(ab_county_dim_0)int640 1 2 3 4 5 6 ... 79 80 81 82 83 84
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84]) - ab_county_dim_1(ab_county_dim_1)int640 1
array([0, 1])
- __log_sigma_slope_dim_0(__log_sigma_slope_dim_0)int640 1
array([0, 1])
- __cholesky_cov_dim_0(__cholesky_cov_dim_0)int640
array([0])
- sigma_slope_dim_0(sigma_slope_dim_0)int640 1
array([0, 1])
- cov_dim_0(cov_dim_0)int640 1
array([0, 1])
- cov_dim_1(cov_dim_1)int640 1
array([0, 1])
- mu_a(chain, draw)float641.39 1.411 1.571 ... 1.627 1.53
array([[1.38981514, 1.41102252, 1.57056486, ..., 1.49308907, 1.62727705, 1.52984406]]) - mu_b(chain, draw)float64-0.5366 -0.5627 ... -0.6235 -0.5805
array([[-0.5366487 , -0.56272015, -0.78026924, ..., -0.62740262, -0.6235238 , -0.58051591]]) - ab_county(chain, draw, ab_county_dim_0, ab_county_dim_1)float641.425 -0.526 1.04 ... 1.495 -0.1514
array([[[[ 1.42506697, -0.52604944], [ 1.03981901, -0.68456314], [ 1.25016548, -0.22305214], ..., [ 1.76422553, -0.89457632], [ 1.57397667, -0.3100903 ], [ 1.53707972, -1.03427611]], [[ 1.21160443, 0.14193781], [ 1.04232542, -0.55043179], [ 1.36190382, -0.50466553], ..., [ 1.63148471, -1.2569052 ], [ 1.34257446, -0.18240088], [ 1.50646085, -0.31975188]], [[ 1.3345931 , -0.69556278], [ 1.0765899 , -0.81404235], [ 1.40043841, -1.11853939], ..., ... ..., [ 2.00472532, -1.36699321], [ 1.5679758 , -0.17008079], [ 1.73254455, -0.26321725]], [[ 1.08675031, -0.46753599], [ 0.86289356, -0.19610458], [ 2.15038148, -0.4468328 ], ..., [ 1.97438806, -0.9933176 ], [ 1.69074963, -0.5830286 ], [ 1.58846354, -0.22340221]], [[ 0.43115089, -0.01547547], [ 1.10117516, -0.27906998], [ 1.74180379, -0.70284035], ..., [ 1.99408171, -1.17529547], [ 1.53073065, -0.52420763], [ 1.49453539, -0.15143056]]]]) - __log_sigma_slope(chain, draw, __log_sigma_slope_dim_0)float64-1.2 -1.078 ... -0.9892 -1.029
array([[[-1.19987902, -1.07827793], [-1.05150271, -0.99156852], [-1.09105603, -1.08172808], ..., [-0.95469953, -1.08248219], [-1.17356413, -1.18389744], [-0.98921242, -1.02942615]]]) - __cholesky_cov(chain, draw, __cholesky_cov_dim_0)float64-0.2201 -0.01191 ... -0.1023
array([[[-0.22008592], [-0.01191335], [-0.0259371 ], ..., [-0.13640177], [-0.28041118], [-0.1022795 ]]]) - __log_sigma(chain, draw)float64-0.3665 -0.3195 ... -0.3517 -0.3739
array([[-0.3665242 , -0.31953318, -0.31282419, ..., -0.31213638, -0.35173813, -0.37388115]]) - sigma_slope(chain, draw, sigma_slope_dim_0)float640.3012 0.3402 ... 0.3719 0.3572
array([[[0.30123065, 0.34018084], [0.34941229, 0.37099432], [0.33586163, 0.33900918], ..., [0.38492779, 0.33875363], [0.30926272, 0.30608347], [0.37186945, 0.35721189]]]) - cov(chain, draw, cov_dim_0, cov_dim_1)float641.0 -0.2149 -0.2149 ... -0.1017 1.0
array([[[[ 1. , -0.21494182], [-0.21494182, 1. ]], [[ 1. , -0.0119125 ], [-0.0119125 , 1. ]], [[ 1. , -0.02592838], [-0.02592838, 1. ]], ..., [[ 1. , -0.1351503 ], [-0.1351503 , 1. ]], [[ 1. , -0.26999703], [-0.26999703, 1. ]], [[ 1. , -0.10174868], [-0.10174868, 1. ]]]]) - sigma(chain, draw)float640.6931 0.7265 ... 0.7035 0.6881
array([[0.69313936, 0.7264881 , 0.73137849, ..., 0.73188171, 0.70346431, 0.68805868]])
- created_at :
- 2020-09-06T15:23:17.272501
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (__cholesky_cov_dim_0: 1, __log_sigma_slope_dim_0: 2, ab_county_dim_0: 85, ab_county_dim_1: 2, chain: 1, cov_dim_0: 2, cov_dim_1: 2, draw: 4000, sigma_slope_dim_0: 2) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 ... 3995 3996 3997 3998 3999 * ab_county_dim_0 (ab_county_dim_0) int64 0 1 2 3 4 ... 81 82 83 84 * ab_county_dim_1 (ab_county_dim_1) int64 0 1 * __log_sigma_slope_dim_0 (__log_sigma_slope_dim_0) int64 0 1 * __cholesky_cov_dim_0 (__cholesky_cov_dim_0) int64 0 * sigma_slope_dim_0 (sigma_slope_dim_0) int64 0 1 * cov_dim_0 (cov_dim_0) int64 0 1 * cov_dim_1 (cov_dim_1) int64 0 1 Data variables: mu_a (chain, draw) float64 1.39 1.411 ... 1.627 1.53 mu_b (chain, draw) float64 -0.5366 -0.5627 ... -0.5805 ab_county (chain, draw, ab_county_dim_0, ab_county_dim_1) float64 ... __log_sigma_slope (chain, draw, __log_sigma_slope_dim_0) float64 -... __cholesky_cov (chain, draw, __cholesky_cov_dim_0) float64 -0.2... __log_sigma (chain, draw) float64 -0.3665 -0.3195 ... -0.3739 sigma_slope (chain, draw, sigma_slope_dim_0) float64 0.3012 ... cov (chain, draw, cov_dim_0, cov_dim_1) float64 1.0 ... sigma (chain, draw) float64 0.6931 0.7265 ... 0.6881 Attributes: created_at: 2020-09-06T15:23:17.272501 arviz_version: 0.9.0xarray.Dataset -
- obs_id: 919
- obs_id(obs_id)int640 1 2 3 4 5 ... 914 915 916 917 918
array([ 0, 1, 2, ..., 916, 917, 918])
- y(obs_id)float640.8329 0.8329 1.099 ... 1.335 1.099
array([ 0.83290912, 0.83290912, 1.09861229, 0.09531018, 1.16315081, 0.95551145, 0.47000363, 0.09531018, -0.22314355, 0.26236426, 0.26236426, 0.33647224, 0.40546511, -0.69314718, 0.18232156, 1.5260563 , 0.33647224, 0.78845736, 1.79175947, 1.22377543, 0.64185389, 1.70474809, 1.85629799, 0.69314718, 1.90210753, 1.16315081, 1.93152141, 1.96009478, 2.05412373, 1.66770682, 1.5260563 , 1.5040774 , 1.06471074, 2.10413415, 0.53062825, 1.45861502, 1.70474809, 1.41098697, 0.87546874, 1.09861229, 0.40546511, 1.22377543, 1.09861229, 0.64185389, -1.2039728 , 0.91629073, 0.18232156, 0.83290912, -0.35667494, 0.58778666, 1.09861229, 0.83290912, 0.58778666, 0.40546511, 0.69314718, 0.64185389, 0.26236426, 1.48160454, 1.5260563 , 1.85629799, 1.54756251, 1.75785792, 0.83290912, -0.69314718, 1.54756251, 1.5040774 , 1.90210753, 1.02961942, 1.09861229, 1.09861229, 1.98787435, 1.62924054, 0.99325177, 1.62924054, 2.57261223, 1.98787435, 1.93152141, 2.55722731, 1.77495235, 2.2617631 , 1.80828877, 1.36097655, 2.66722821, 0.64185389, 1.94591015, 1.56861592, 2.2617631 , 0.95551145, 1.91692261, 1.41098697, 2.32238772, 0.83290912, 0.64185389, 1.25276297, 1.74046617, 1.48160454, 1.38629436, 0.33647224, 1.45861502, -0.10536052, ... 1.80828877, 1.09861229, 1.91692261, 2.96527307, 1.41098697, 1.79175947, 2.20827441, 2.14006616, 0.18232156, 1.16315081, 2.4510051 , 2.27212589, 1.09861229, -0.22314355, 1.19392247, 1.56861592, 1.58923521, -0.69314718, 2.24070969, 0.58778666, 0. , 2.3321439 , 2.05412373, 0.83290912, 1.88706965, 2.50959926, 1.54756251, 1.84054963, 1.88706965, 1.06471074, 0.69314718, 0.26236426, 0.91629073, 0.09531018, 0.26236426, 0.53062825, -0.10536052, 0.58778666, 1.56861592, 0.58778666, 1.22377543, -0.10536052, 2.29253476, 1.68639895, 2.1517622 , 0.69314718, 1.90210753, 1.36097655, 1.79175947, 1.60943791, 0.95551145, 2.37954613, 0.91629073, 0.78845736, 1.56861592, 1.33500107, 2.60268969, 1.09861229, 1.48160454, 1.36097655, 0.64185389, 0.47000363, 0.64185389, 0.33647224, 1.90210753, 3.02042489, 1.80828877, 2.63188884, 2.3321439 , 1.75785792, 2.24070969, 1.25276297, 1.43508453, 2.45958884, 1.98787435, 1.56861592, 0.64185389, -0.22314355, 1.56861592, 2.3321439 , 2.43361336, 2.04122033, 2.4765384 , -0.51082562, 1.91692261, 1.68639895, 1.16315081, 0.78845736, 2.00148 , 1.64865863, 0.83290912, 0.87546874, 2.77258872, 2.2617631 , 1.87180218, 1.5260563 , 1.62924054, 1.33500107, 1.09861229])
- created_at :
- 2020-09-06T15:23:17.277314
- arviz_version :
- 0.9.0
<xarray.Dataset> Dimensions: (obs_id: 919) Coordinates: * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 ... 911 912 913 914 915 916 917 918 Data variables: y (obs_id) float64 0.8329 0.8329 1.099 0.09531 ... 1.629 1.335 1.099 Attributes: created_at: 2020-09-06T15:23:17.277314 arviz_version: 0.9.0xarray.Dataset
az.plot_forest(
[
varying_intercept_slope_samples,
covariation_intercept_slope_samples,
covariation_intercept_low_rank_samples,
covariation_intercept_low_rank_150_samples,
covariation_intercept_full_rank_samples
],
model_names=["No covariation", "Mean Field", "Low Rank(50)", "Low Rank(150)", "Full Rank"],
var_names=["cov"],
combined=True,
figsize=(6.5, 8),
);

We can see a negative coorelation as the mean of correlation matrix lies around -0.25. This means when the intercept increases, the slope decreases. Interestingly, by increasing the rank for LowRank ADVI, the correlation is getting close to that in case of FullRank ADVI one.
a_county_cov = covariation_intercept_full_rank_samples.posterior["ab_county"].mean(dim=("chain", "draw"))[:, 0]
b_county_cov = covariation_intercept_full_rank_samples.posterior["ab_county"].mean(dim=("chain", "draw"))[:, 1]
# plot both and connect with lines
plt.scatter(avg_a_county, avg_b_county, label="No cov estimates", alpha=0.6)
plt.scatter(
a_county_cov,
b_county_cov,
facecolors="none",
edgecolors="k",
lw=1,
label="With cov estimates",
alpha=0.8,
)
plt.plot([avg_a_county, a_county_cov], [avg_b_county, b_county_cov], "k-", alpha=0.5)
plt.xlabel("Intercept")
plt.ylabel("Slope")
plt.legend();

Interestingly, the differences between both models occur at extreme slope and intercept values. This is because the second model used the slightly negative correlation between intercepts and slopes to adjust their estimates and brings out more information from the data.
- Mean Field tends to scale better to larger datasets where correlation between parameters is not much concerned.
- Fitting data with FullRank can capture very good correlations on par with MCMC but comes with its own computational problems.
- LowRank ADVI can be seen as a mid-way of both extremes.
TODO¶
Perform waic and loo tests to compare models. I need to learn about this.
%load_ext watermark
%watermark -n -u -v -iv -w
pandas 1.1.1 arviz 0.9.0 tensorflow 2.4.0-dev20200905 pymc4 4.0a2 logging 0.5.1.2 xarray 0.16.0 numpy 1.18.5 last updated: Sun Sep 06 2020 CPython 3.8.5 IPython 7.18.1 watermark 2.0.2